The Legendre transform is a mechanism for converting a relationship like

into a relationship like

In other words, by going from a function 



In moving from (1) to (2), the required Legendre transform is

because differentiating both sides of (3) with respect to


Using (1), we see that the last two terms in (4) cancel, so we get (2). Conversely, the Legendre transform of

because differentiating both sides with respect to
The Fenchel-Legendre transform in large deviation theory achieves this same kind of relationship between an entropy function 

We take 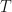


Random variables for which we can use (7) as an approximation of the density at tail values
One way to understand how (6) arises is in terms of Chernoff’s inequality, which says

Chernoff’s inequality is a modified form of Markov’s inequality. Minimising the upper bound in this inequality requires
Another way to understand where (6) comes from is through the use of the approximation in (7) to obtain
![E[e^{kT}] = \int_{\mathbb{R}} e^{kT} f(T) dT \qquad \qquad \qquad (9)](https://s0.wp.com/latex.php?latex=E%5Be%5E%7BkT%7D%5D+%3D+%5Cint_%7B%5Cmathbb%7BR%7D%7D+e%5E%7BkT%7D+f%28T%29+dT+%5Cqquad+%5Cqquad+%5Cqquad+%289%29&bg=ffffff&fg=111111&s=0&c=20201002)
(Note that, by the inherent symmetry, the right-hand side can equally be regarded as the Laplace transform of the density). We now approximate 
![f(\bar{T})d \bar{T} = P(T \in [\bar{T}, \bar{T}+d\bar{T}]) \qquad \qquad \qquad (10)](https://s0.wp.com/latex.php?latex=f%28%5Cbar%7BT%7D%29d+%5Cbar%7BT%7D+%3D+P%28T+%5Cin+%5B%5Cbar%7BT%7D%2C+%5Cbar%7BT%7D%2Bd%5Cbar%7BT%7D%5D%29+%5Cqquad+%5Cqquad+%5Cqquad+%2810%29&bg=ffffff&fg=111111&s=0&c=20201002)
with 
![E[e^{kT}] \approx \int_{\mathbb{R}} e^{k \bar{T}} e^{-J(\bar{T})} d\bar{T} = \int_{\mathbb{R}} e^{k\bar{T} - J(\bar{T})}d \bar{T} \qquad \qquad \qquad (11)](https://s0.wp.com/latex.php?latex=E%5Be%5E%7BkT%7D%5D+%5Capprox+%5Cint_%7B%5Cmathbb%7BR%7D%7D+e%5E%7Bk+%5Cbar%7BT%7D%7D+e%5E%7B-J%28%5Cbar%7BT%7D%29%7D+d%5Cbar%7BT%7D+%3D+%5Cint_%7B%5Cmathbb%7BR%7D%7D+e%5E%7Bk%5Cbar%7BT%7D+-+J%28%5Cbar%7BT%7D%29%7Dd+%5Cbar%7BT%7D+%5Cqquad+%5Cqquad+%5Cqquad+%2811%29&bg=ffffff&fg=111111&s=0&c=20201002)
We can approximate the integral in (11) using the saddle-point approximation, i.e., as the maximum value of the integrand, which gives
![E[e^{kT}] \approx \exp(\sup_{\bar{T} \in \mathbb{R}} (k\bar{T} - J(\bar{T}))) \qquad \qquad \qquad (12)](https://s0.wp.com/latex.php?latex=E%5Be%5E%7BkT%7D%5D+%5Capprox+%5Cexp%28%5Csup_%7B%5Cbar%7BT%7D+%5Cin+%5Cmathbb%7BR%7D%7D+%28k%5Cbar%7BT%7D+-+J%28%5Cbar%7BT%7D%29%29%29+%5Cqquad+%5Cqquad+%5Cqquad+%2812%29&bg=ffffff&fg=111111&s=0&c=20201002)
Now taking the log of both sides of this we get

We can now get from (13) to (6) by invoking the Legendre transform relationship. To do this, we need to carefully understand the role that taking the supremum is playing in (13). For any given value of 

where 

where 
