A mathematics and physics `scrapbook', with notes on miscellaneous things that catch my interest in a range of areas including: mathematical methods; number theory; probability theory; stochastic processes; mathematical economics; econometrics; quantum theory; relativity theory; cosmology; cloud physics; statistical mechanics; nonlinear dynamics; electronic engineering; graph and network theory; mathematics in Latin; computational mathematics using Python and other maths software.
Study of a Lagrangian function approach to analysing raindrop growth
In this note, I study a constrained maximisation approach seeking to clarify the growth history of microscopic water droplets which undergo runaway aggregation to become raindrops. Using this approach, and the setup outlined in a previous note about a 2016 paper in Physical Review Letters on the large deviation analysis of rapid-onset rain showers (referred to as MW2016 herein), an expression for the total time for runaway growth is easily obtained in terms of the mean inter-collision times . This expression seems to be related in some way to the expression for in MW2016, which was derived from large deviation analysis. The purpose of the present note is to try to further clarify the links with some of the results in MW2016. In order to achieve this, I employed a Lagrangian function approach to the constrained maximisation problem as follows.
A Lagrangian function approach
Let the random variable , representing the total time required for a droplet to undergo runaway growth, be defined as in the previous note mentioned above, that is,
where the inter-collision times are independent exponentially distributed random variables with mean . The parameter is a given total number of water particle collisions required for runaway growth of a raindrop.
Consider also a fixed time interval , where , and is a number in the small-value tail of the distribution of , to be treated as an exogenous parameter in the forthcoming analysis. We partition the interval into subintervals, each of length , so that
Then on the basis of the exponential distributions of the inter-collision times , we have the following joint cumulative distribution function for the inter-collision times:
In the constrained maximisation approach, we seek to choose the inter-collision time parameters to maximise the joint cumulative distribution function in (2), subject to the constraint represented by (1). Since logarithms are monotone increasing functions, we can obtain the same results by maximising the natural logarithm of (2) subject to (1). The Lagrangian function for this constrained maximisation problem can then be written as
where I have used the symbol to denote the Lagrange multiplier, since this will turn out to be closely linked to the Laplace transform parameter in the large deviation analysis in MW2016. First-order conditions for a maximum are
for , and
Solving (4) gives
and putting this into (5) gives
where and denote the optimised values of and respectively, given the value of the parameter . We can now put this structure to work and clarify its links with runaway growth of raindrops and with the large deviation analysis in MW2016.
First, we obtain an intuitively appealing interpretation of the optimised Lagrange multiplier by solving (6) for in the case . Noting that , this gives
Therefore, for small and , we have , so the maximised Lagrange multiplier can be interpreted as the reciprocal of the first monomer collision time in the runaway growth process. Thus, can be expected to be very large in scenarios in which is very small.
Next, put the expressions for in (6) into the Lagrangian function in (3), to obtain the following expression for the maximised value of the Lagrangian as a function only of :
In the regime of a small , , and , the second term on the right-hand side of (9) would converge to the constant , and we recognise the first bracketed term on the right-hand side of (9) as being of the same form as the entropy function in MW2016. Therefore, as , and , we obtain the result
which then leads to the same function as the one derived from the large deviation analysis in MW2016. However, in the regime of larger values of for which is not large, the correct expression for is (7) above, obtained when the second term on the right-hand side of (9) is no longer negligible when calculating .
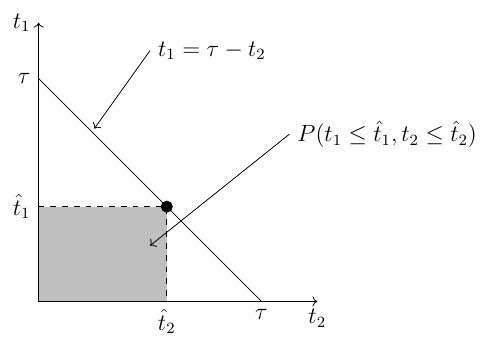
A geometric understanding of the relationship between the two approaches can also be obtained by recognising a probabilistic connection between them. We can extend to our -dimensional case an elementary result in probability theory relating the cumulative distribution function of a sum of random variables to the joint density function of those same random variables by writing
Given that the inter-collision times are independent, the integrand on the right-hand side of (11) is the joint probability density function of the inter-collision times , which also appear in the sum in the cumulative distribution function on the left-hand side of (11). To clarify the situation geometrically, consider the two-dimensional case depicted in the following diagram.
In two dimensions, the probability represented by (11) is the probability mass in the shaded region bounded by the coordinate axes and the diagonal line.
The link between this framework, and the exponential function of the entropy function that appears in the large deviation analysis in MW2016, , is that the latter has the probabilistic interpretation that it is the smallest possible upper bound of the probability that the random sum of inter-collision times is greater than when using the form of Markov’s inequality in the Cramér-Chernoff bounding method (see my previous note about this}. Therefore, negating this relationship, we have
So, by using the Fenchel-Legendre transform , the approach in MW2016 is implicitly maximising the lower bound of the probability that the sum of inter-collision times is no greater than in (12), and then constitutes an approximation of the probability mass represented in two dimensions by the shaded region in the diagram above.
The link with the constrained maximisation approach is that here we are approximating the probability as represented by the right-hand side of (11) by choosing the parameters to obtain the maximum of the joint cumulative distribution function of the inter-collision times. In the two-dimensional case, this corresponds to choosing a point on the diagonal line in the diagram below in order to maximise the probability mass in the rectangular region.
The upshot, then, is that the multi-dimensional analogue of maximising the probability mass in the rectangular region in the second diagram above by choosing the optimally, and the multi-dimensional analogue of approximating the probability mass in the entire region below the diagonal line using the entropy function in , both converge to the same result in the small and small regime for which . The two approaches deviate from each other in the large /small regime due to the logarithmic correction term in (9).
Finally in this section, I briefly record some numerical results from using MAPLE to implement equations (6) and (7). Substituting equation (8) into (6) and (7), and using , we obtain
for , and
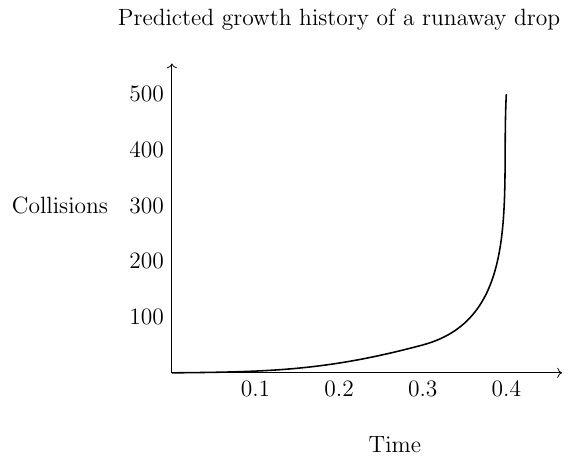
Thus, given a value for , the maximum-likelihood time for the first monomer collision can be computed from (14), and then this value can be used to determine for each via (13). A plot of the number of collisions versus time, i.e., the growth history of a runaway drop, can then be obtained by plotting the points with coordinates for . For example, a MAPLE computation with values and , inspired by some FORTRAN simulations, produced a first monomer collision time and a growth history plot like the one shown in the following diagram. The shape of this plot is typical of the runaway growth plots also produced by some physical FORTRAN simulations (not shown here).
Interpretation as constrained maximum likelihood
At first sight, the constrained maximisation approach in this section looks different from a traditional maximum likelihood calculation because the objective function (2) involves the cumulative distribution functions of the inter-collision times rather than probability densities. However, the approach can in fact be interpreted as a constrained maximum likelihood problem with left-censoring of the inter-collision times. Censored data arise frequently in econometrics and other statistical disciplines when some values of a variable of interest fall within a certain range that renders them unobservable. Such observations are then all reported in a collected data set as having a value equal to the boundary of the unobservable range. The objective functions used for maximum likelihood estimation in these settings will necessarily involve the cumulative distribution functions of the variables of interest, because probability densities cannot be evaluated at single points for censored data. See, for example, Gentleman, R., Geyer, C., 1994, Maximum likelihood for interval censored data: consistency and computation, Biometrika, Vol. 81, No. 3, pp. 618-623, and also pages 761-768 in Greene, W., 2003, Econometric Analysis, Fifth Edition, Prentice-Hall International (UK) Limited, London.
In our constrained maximisation calculation in this section, what we are essentially saying is this: we cannot observe the actual inter-collision times , so assume that all we know is that the inter-collision times are below some threshold values . (In econometrics, this would be referred to as left-censoring). Then given the exponential distributions for the inter-collision times, what is the most likely sequence of threshold values for a runaway raindrop? It is important to understand, however, that we are not addressing this question here in a statistical way with observed data. Maximum likelihood estimation has some well known disadvantages in statistical contexts, particularly when the number of parameters to be estimated is large. Distortions can arise in maximum likelihood estimation involving the gamma distribution, for example, due to unwanted correlations between parameter estimates. See, e.g., Bowman, K., Shenton, L., 2002, Problems with maximum likelihood estimation and the 3 parameter gamma distribution, Journal of Statistical Computation and Simulation, 72:5 pp. 391-401. However, we are not doing statistical maximum likelihood here, in the sense that we are not using observed data to estimate parameters. We are doing mathematical maximum likelihood, just using the functional forms of the probability distributions of the runaway drops. In this context, the statistical problems with the maximum likelihood method are irrelevant, so the approach here actually represents a potentially powerful mathematical method for analysing raindrop histories that can also be applied in the context of other problems. It also has direct links to the entropy functions of large deviation theory, as was demonstrated using the Lagrangian function approach above.


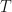




![[0, \tau]](https://s0.wp.com/latex.php?latex=%5B0%2C+%5Ctau%5D&bg=ffffff&fg=111111&s=0&c=20201002)