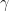A mathematics and physics `scrapbook', with notes on miscellaneous things that catch my interest in a range of areas including: mathematical methods; number theory; probability theory; stochastic processes; mathematical economics; econometrics; quantum theory; relativity theory; cosmology; cloud physics; statistical mechanics; nonlinear dynamics; electronic engineering; graph and network theory; mathematics in Latin; computational mathematics using Python and other maths software.
A spline approximation scheme for large deviation theory problems
In this note, I develop and implement a spline function approximation scheme that can quickly generate accurate benchmark solutions for large deviation theory problems. To my knowledge, spline function approximation methods have not been applied before in the context of large deviation theory. This note shows that such methods can be efficient and effective even when it is computationally difficult or impossible to obtain the required numerical results in other ways.
In fact, the effort in this note was initially motivated by computational difficulties encountered while trying to obtain fine-grained sets of numerical values for the large deviation functions in a 2016 paper in Physical Review Letters (outlined in a previous note) about the large deviation analysis of rapid-onset rain showers. This paper will be referred to as MW2016 herein. It is desirable to carry out such computations using sophisticated mathematical software systems such as MAPLE, which come with many built-in features that can make the necessary programming convenient and transparent. However, attempts to compute fine-grained exact function values for the cumulant generating function and its derivatives proved to be difficult and time consuming in MAPLE. Carrying out these computations for the case took hours and it was even more time consuming to obtain the necessary fine-grained exact function values for the case . In view of these difficulties, it seemed desirable to attempt to develop a new numerical solution system for large deviation problems that would enable accurate numerical results to be produced in MAPLE, using only the simplest mathematical functions. This note reports my experiments with one way of achieving this using cubic spline functions.
A closer look at the cumulant generating function
For what follows, assume the same simple power law collision rates as in MW2016, with the normalisations and . Also assume a given collision rate parameter , and that . The cumulant generating function in equation [14] in MW2016 is then a smooth, strictly concave function in both and . To see this, write it as
The first two partial derivatives with respect to are
and
which confirms strict concavity with respect to . To find the partials with respect to , we can use the Euler-Maclaurin formula to express (1) as
where , are the even-indexed Bernoulli numbers, and is a remainder term. Numerical experiments with MAPLE indicate that only the first two terms on the right-hand side of the Euler-Maclaurin formula are needed to obtain accurate approximations of our cumulant generating function over the entire range of relevant values of , and . Thus, to a close approximation we have
Using Liebniz’s Rule, we can now obtain the first two partials with respect to as
and
which confirms strict concavity with respect to . The cross-partial derivative is
For completeness, the first two partials with respect to the collision rate parameter , using (1), are obtained as
and
Thus, the cumulant generating function is a strictly convex function of .
The following is a three-dimensional MAPLE plot of the cumulant generating function for , , and :
A simple idea from differential geometry
It is known in classical differential geometry that a smooth and strictly concave curve has an osculating parabola at each of its points. (See, e.g., Har’el, Z., 1995, Curvature of Curves and Surfaces – A Parabolic Approach, URL: http://harel.org.il/zvi/docs/parabola.pdf, and references therein). In particular, the curve at each point should match a Taylor expansion of the function around that point at least up to second-order. Some experiments in MAPLE indicated that remarkably accurate fits to the strictly concave -curves of the cumulant generating function can indeed be obtained using second-order Taylor expansions with respect to , for given values of and . For example, the following are some 3D MAPLE plots showing closely fitting quadratic Taylor polynomials to different parts of the -curve for and :
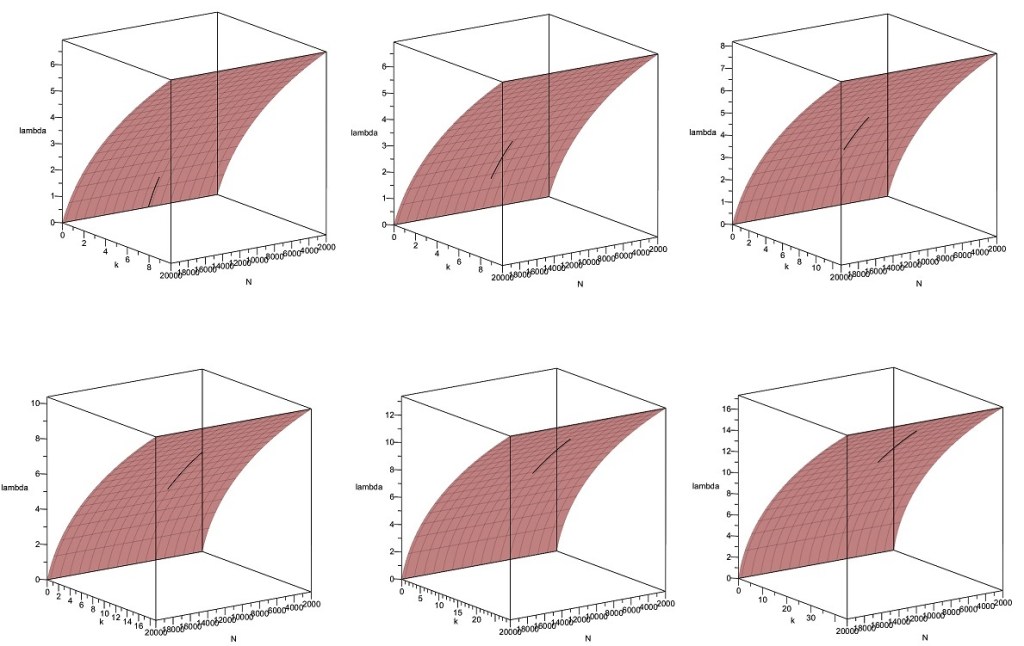
In these plots, the osculating quadratic Taylor expansions of with respect to are shown centered at different points along the -curve. When just fifteen such quadratic pieces are spliced together, they form a quadratic spline providing an essentially perfect approximation of the cumulant generating function from to , as shown below:
This suggests that numerical approximation schemes involving spline functions might be highly effective for the cumulant generating function in MW2016, and this indeed proved to be the case as discussed below.
Within each of the parabolic segments in the above plots, the cumulant generating function behaves to a very close approximation like a simple quadratic in . In fact, this applies at every point of the cumulant generating function, i.e., for every relevant value of and , and indeed for every relevant value of . Before embarking on the development of spline function approximation techniques, it therefore seems desirable to try to understand better how the large deviation theory in MW2016 manifests itself in this simple quadratic setup. To this end, suppose that and are given, and consider a point on the corresponding -curve of the cumulant generating function. There will be a parabolic segment around this point within which the cumulant generating function behaves exactly like the following quadratic in :
The coefficients here are just (1), (2) and (3) above, evaluated at the given values of and , and at . To simplify notation in what follows, we will write the partial derivatives in (11) as
and
The entropy function in MW2016 is
Differentiating the expression in curly brackets with respect to and setting equal to zero in order to find , using (11) above, we obtain
This expression is interesting for two reasons. First, recall that for any given there is a unique . Suppose we are in fact within the parabolic segment containing for such a given value of . If the centre of the Taylor expansion for that particular parabolic segment is slightly away from , then the required correction for the given is represented by the second term in (15) above, which involves . There is no correction needed if , and this happens when in (15) above. But this is exactly the saddlepoint condition in equation [16] in MW2016, so one of the key equations in the large deviation theory in MW2016 has now appeared naturally in this simple quadratic setup.
The second reason that (15) seems interesting is that it resembles the well known Newton-Raphson formula used for solving equations iteratively. This suggests that (15) might actually provide an efficient way of solving in order to find exact values of for different values of . Experiments in MAPLE do indeed confirm that (15) is a useful formula for quickly obtaining values of , particularly in the case with large values of , say . Using the Maximize command in MAPLE’s Optimization package, with the right-hand side of (15) as the objective function and given values of one very quickly obtains values of as the maximised values of the objective function. This approach is much faster in the case than using MAPLE’s fsolve command directly with formula [16] in MW2016, though fsolve does work well in the case .
Putting (15) into (11) and simplifying we get
Again, we can regard the second term here as the correction needed when the centre of the Taylor expansion is not quite equal to the optimal value . Putting (16) into (14), we get the entropy function as
where again the last term is a correction, and, finally, the saddlepoint density in [17] in MW2016 is obtained here as
This analysis indicates how the large deviation theory in MW2016 can be linked to a simple quadratic spline approximation of the cumulant generating function. The question now is how to implement these ideas computationally to obtain a spline function approximation approach which can be used to obtain rapid and accurate quantitative results for any desired values of , , and . A simple scheme immediately suggests itself, as described in the next section.
A spline approximation approach for MAPLE
The following spline function approximation approach for MAPLE implements the insights from the previous sections, and proves to work extremely well in the sense that it produces highly accurate results, very quickly, using only the simplest polynomials, and for any desired values of , , and :
a). First, we obtain a small sample of exact values of corresponding to some given values of between 0.01 and 2.00, using equation [16] in MW2016 or equation (15) above. Experiments show that 40 sample values are ample for highly accurate spline approximations. These sample values can be obtained very quickly using MAPLE’s fsolve or Maximize commands, as indicated in the previous section.
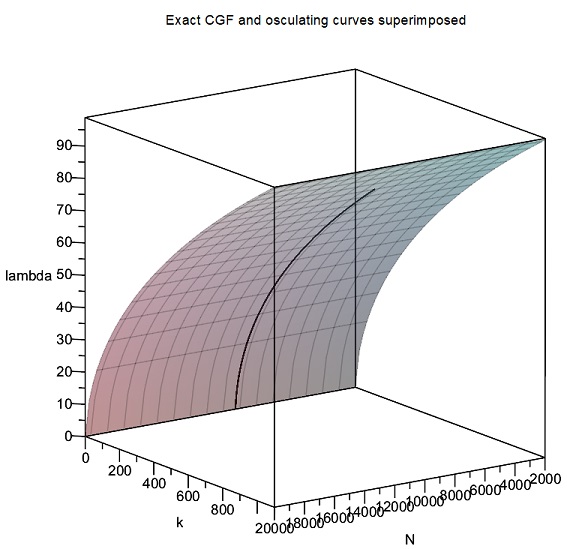
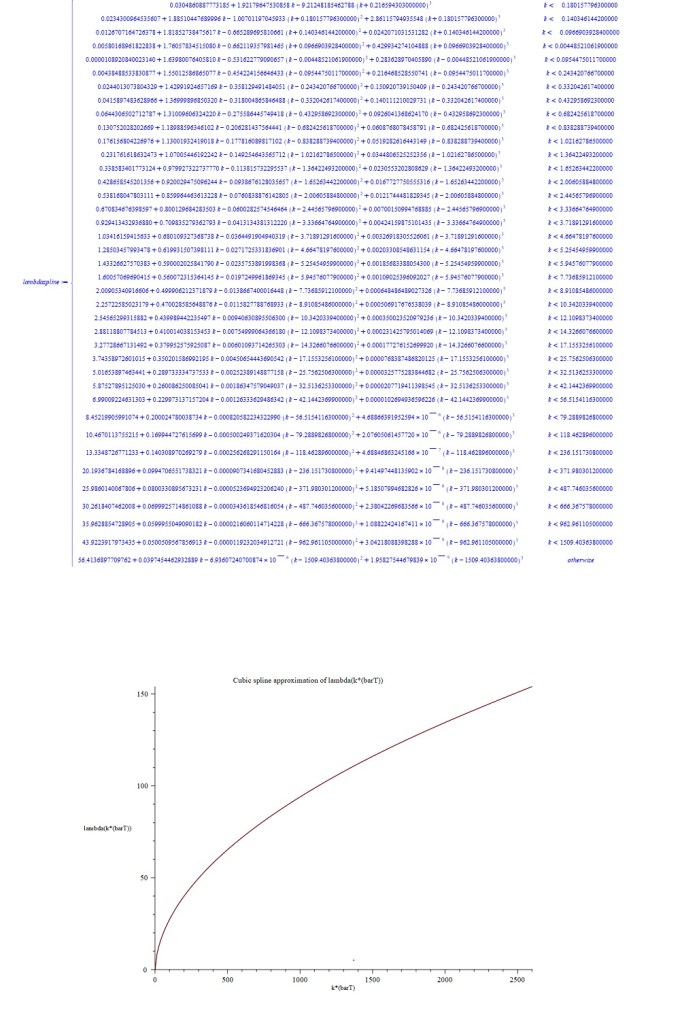
b). Second, we use this small sample of exact values to create spline function representations of and , analogous to the quadratic spline created manually for the cumulant generating function in the previous section. This quadratic spline worked very well due to the smoothness and well-behaved nature of the cumulant generating function, but even more accurate results can be obtained with cubic splines. MAPLE routines can be written which can generate such cubic spline approximations very quickly.
c). Next, we obtain the first and second derivatives of the spline function representation of . The component pieces of this spline will all be simple cubics, so this differentiation exercise is handled very quickly by MAPLE.
d). Finally, using the cubic spline function representation of , we can now generate fine-grained numerical data by evaluating for as many values of as desired, and we can also obtain the corresponding values of the spline representation of and its derivatives. These can then be used to compute sets of fine-grained numerical values for the entropy function and the log-saddlepoint-density function . (The term fine-grained is used here to mean approximately 200 values of the relevant functions, or more, corresponding to values of in the range 0.0 to 2.0). Note that an immediate check of accuracy can be performed at this stage by comparing the values of the first derivative of the spline , evaluated at the fine-grained values of the spline , with the corresponding values of . They should closely agree if the splines are accurately interpolating the corresponding exact function values.
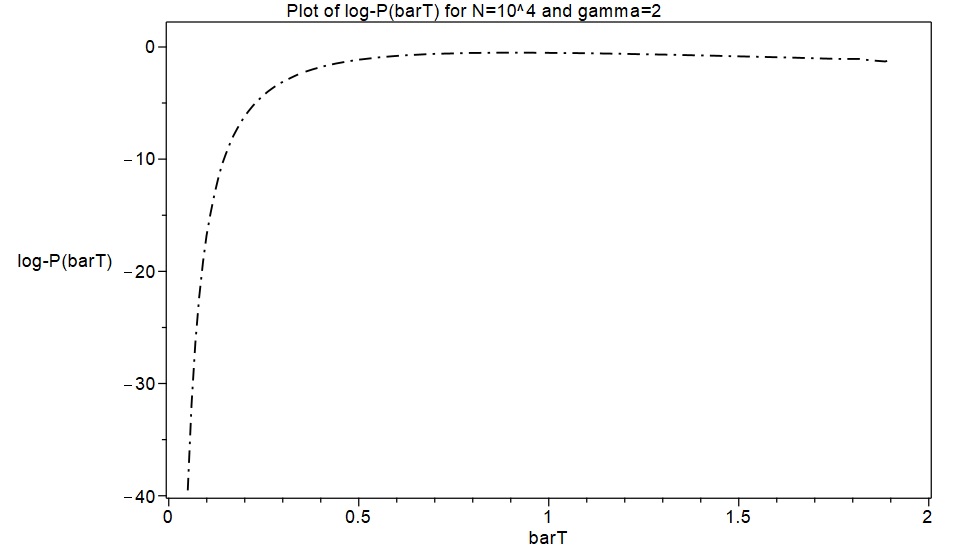
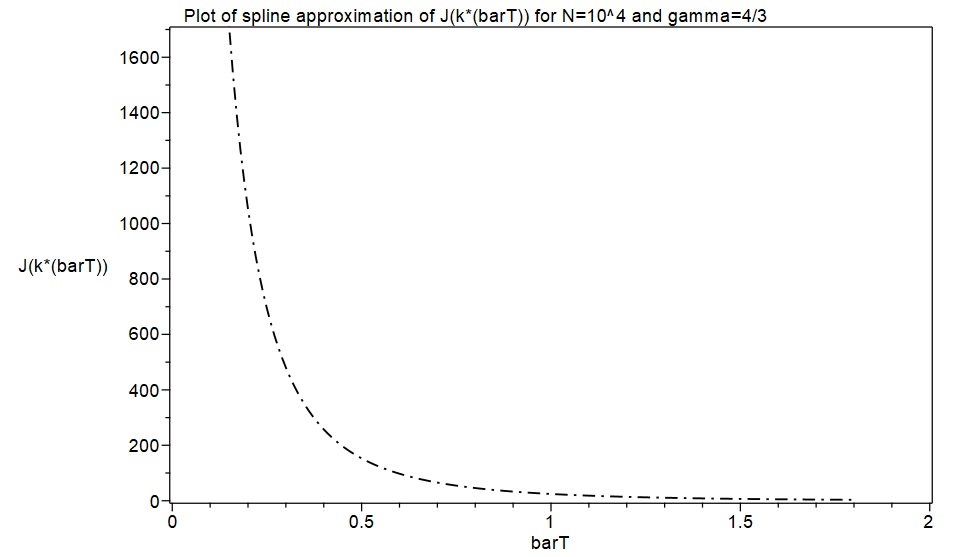
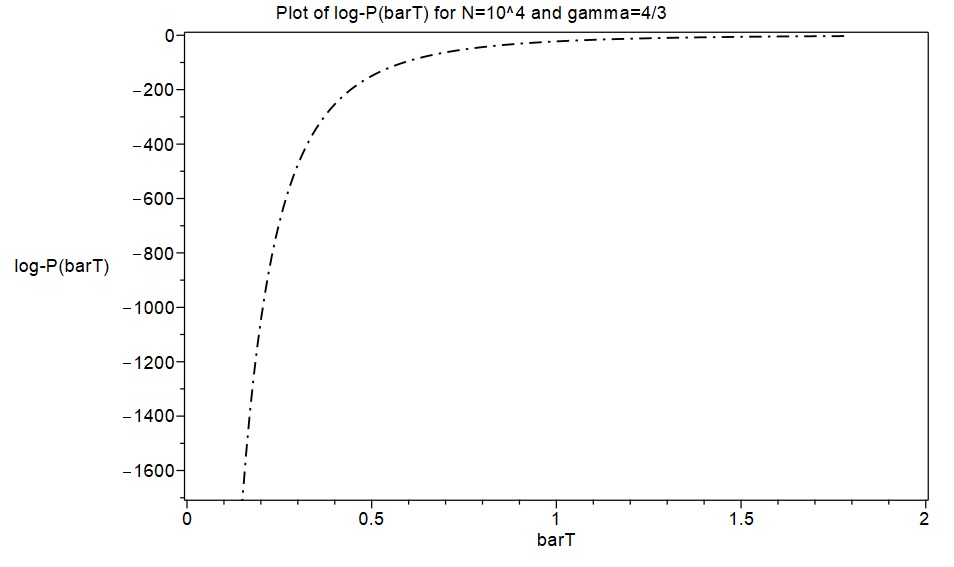
As a first excursion with this new approximation approach, an attempt was made to replicate the results in MW2016 for the cases and , with . Spline function representations of and consisting of 40 cubic pieces were quickly obtained with initial samples of 40 exact values of . These are displayed below as piecewise functions for the case , together with plots of the corresponding splines. The derivatives of were then calculated, and these were used to calculate the entropy functions and the log-saddlepoint-density functions, finally obtaining plots of these which are also shown below for the cases and .
Note that, despite the computational difficulties encountered when trying to compute exact function values for the case in particular, obtaining the corresponding cubic spline function approximations proved to be just as quick and easy as for the case .
Checking accuracy of splines and asymptotic formulae
In the previous section, a solution system was developed based on spline function approximations that can quickly and accurately solve the large deviation problems we are interested in, for any values of , , and , even when these solutions are computationally difficult or impossible to obtain in a fine-grained way using exact functions. This gives us a machine for quickly generating accurate benchmark solutions which, for example, can be compared with analytical work.
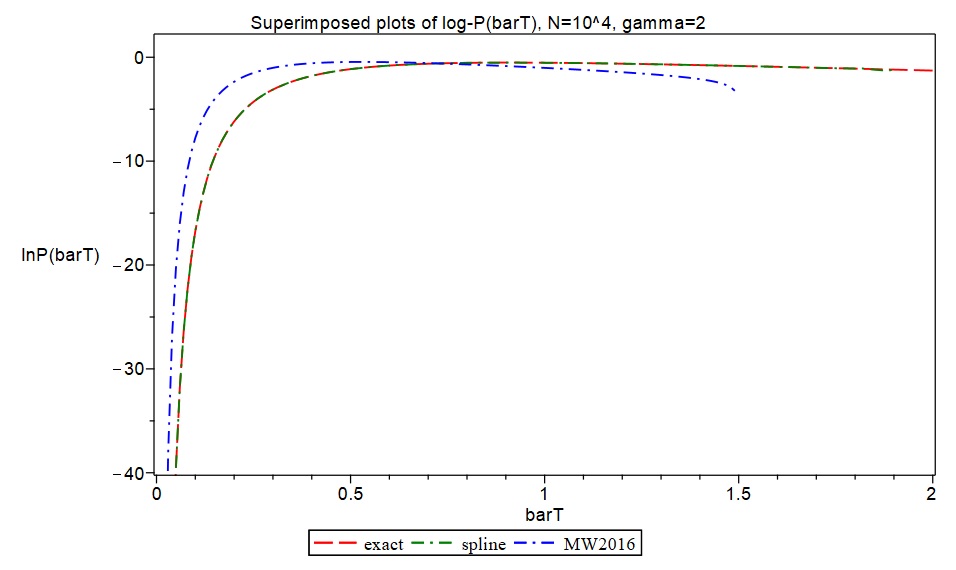
I decided to try to put both the spline function approach and the asymptotic formulae in MW2016 to the test by producing fine-grained exact values for the relevant functions (i.e., approximately 200 function values for values of in the range 0.0 to 2.0), and then comparing our approximations with these. I was able to obtain fine-grained exact values for the case and in MAPLE, and this took a significant amount of computation time using the relevant exact functions. In contrast, it only took a few minutes to produce corresponding spline function approximations to an equally fine-grained degree, i.e. approximately 200 values, with a discretization based on 40 values of , giving a sample of 40 exact values of . I also used formulas [19] and [21] in the Supplement to MW2016 to generate corresponding data based on MW’s asymptotic formulae. I then produced superimposed plots of the exact data, the spline function approximations, and the asymptotic formulae in MW2016 to visually assess accuracy.
As shown in the following plots, the spline function approximations produced results in a few minutes which are essentially indistinguishable from the exact values obtained after numerous hours of computation in MAPLE. However, the asymptotic formulae in MW2016 (plots shown in blue) produced rather inaccurate approximations for and .
In the case , obtaining fine-grained exact data is computationally very time consuming in MAPLE. Exact formula computations take a lot longer with than with , and producing a fine-grained set of around 200 exact values for all the required functions with and takes a large amount of computing time. However, the spline approximation approach produced such fine-grained results again in only a few minutes. In lieu of fine-grained exact function values, I used MAPLE to generate six exact function values for the case and , and I plotted these as discrete points together with the spline functions to provide some degree of comparison with exact data. The results again indicate that the spline approximations are highly accurate representations of what fine-grained exact results would have looked like.
I also decided to compare the asymptotic formulae in MW2016 with the spline approximations and exact function values. I used formulae [19] and [24] in the Supplement to MW2016 for this. (MW asserts there that formula [24] produces more accurate asymptotic approximations than formula [21] in the case ). In the following plots, the spline function approximations are shown in green and MW’s asymptotic formulae in blue. The six exact function values are plotted as discrete red points. As in the case , the spline functions seem to be accurately representing the exact results, while the asymptotic formulae in MW2016 are clearly producing inaccurate results here. The discrepancies between the asymptotic formulae and the spline approximations/exact values seem a lot worse for than for , with .
On the basis of these accuracy checks, there is therefore little question that the asymptotic formulae in MW2016 are producing rather inaccurate results in the case for both and when compared with both exact function values and my spline approximations, notwithstanding the favourable-looking numerical simulation results reported in MW2016 for log-densities. (I have communicated these results to Michael Wilkinson, the author of MW2016).





![\gamma \in [4/3,2]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%5B4%2F3%2C2%5D&bg=ffffff&fg=111111&s=0&c=20201002)