Let  denote an
denote an  data matrix, e.g., observations on
data matrix, e.g., observations on  variables for
variables for  individuals. In what follows, we assume has been centered at zero, i.e., each element of the original uncentered data matrix has had the mean of its column subtracted from it to form the corresponding element of . If
individuals. In what follows, we assume has been centered at zero, i.e., each element of the original uncentered data matrix has had the mean of its column subtracted from it to form the corresponding element of . If  denotes the transpose of , then the
denotes the transpose of , then the  matrix
matrix  is
is 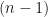 -times the covariance matrix of the data. Since is symmetric, it has real nonnegative eigenvalues which we will denote by
-times the covariance matrix of the data. Since is symmetric, it has real nonnegative eigenvalues which we will denote by  for
for  , and corresponding orthonormal eingenvectors
, and corresponding orthonormal eingenvectors  , . It is customary to order these so that
, . It is customary to order these so that  , and we can then write the eigenvalue equations in matrix form as
, and we can then write the eigenvalue equations in matrix form as

where  is a matrix whose columns are the normalised eigenvectors of , and
is a matrix whose columns are the normalised eigenvectors of , and  is a diagonal matrix with the eigenvalues in descending order of size along the main diagonal.
is a diagonal matrix with the eigenvalues in descending order of size along the main diagonal.
In Principal Components Analysis (PCA), the eigenvectors of are referred to as the principal directions of the centered data matrix . The principal components of the data matrix are the projections  of the data set onto its principal directions. The product matrix
of the data set onto its principal directions. The product matrix  is thus used for data dimensionality reduction. The idea is that the first two or three columns of the principal components matrix might capture most of the variation between the individuals in the data set, this variation being measured by the corresponding eigenvalues in the diagonal matrix . We can then produce a two or three-dimensional scatter plot of the data, with each individual in the rows of having a point in the scatter plot with coordinates appearing in the first two or three columns of along that row. The remaining columns in can be ignored since they do not vary much between the individuals, so the large data set has been reduced to a convenient two or three dimensional scatterplot displaying most of the variation in the data set.
is thus used for data dimensionality reduction. The idea is that the first two or three columns of the principal components matrix might capture most of the variation between the individuals in the data set, this variation being measured by the corresponding eigenvalues in the diagonal matrix . We can then produce a two or three-dimensional scatter plot of the data, with each individual in the rows of having a point in the scatter plot with coordinates appearing in the first two or three columns of along that row. The remaining columns in can be ignored since they do not vary much between the individuals, so the large data set has been reduced to a convenient two or three dimensional scatterplot displaying most of the variation in the data set.
The spectral decomposition of the matrix is thus

which can be written equivalently as

But note that  is the covariance matrix of . This shows that the eigenvalues of along the diagonal of are the variances of the columns of the principal components matrix , and remember these are arranged in descending order of size. Furthermore, the principal directions represented by the eigenvectors of are the directions in which the data are maximally dispersed, i.e., the total dispersion cannot be increased by choosing any other matrix
is the covariance matrix of . This shows that the eigenvalues of along the diagonal of are the variances of the columns of the principal components matrix , and remember these are arranged in descending order of size. Furthermore, the principal directions represented by the eigenvectors of are the directions in which the data are maximally dispersed, i.e., the total dispersion cannot be increased by choosing any other matrix  instead of which satisfies
instead of which satisfies  . To clarify this, note that
. To clarify this, note that
![\text{tr}[(\mathbf{X} \mathbf{V})' (\mathbf{X} \mathbf{V})] = \text{tr}(\mathbf{V}' \mathbf{X}'\mathbf{X}\mathbf{V}) = \text{tr}(\mathbf{X}'\mathbf{X}\mathbf{V}\mathbf{V}') \leq \sum_{i=1}^k \lambda_i(\mathbf{X}'\mathbf{X}) \lambda_i(\mathbf{V}\mathbf{V}')](https://s0.wp.com/latex.php?latex=%5Ctext%7Btr%7D%5B%28%5Cmathbf%7BX%7D+%5Cmathbf%7BV%7D%29%27+%28%5Cmathbf%7BX%7D+%5Cmathbf%7BV%7D%29%5D+%3D+%5Ctext%7Btr%7D%28%5Cmathbf%7BV%7D%27+%5Cmathbf%7BX%7D%27%5Cmathbf%7BX%7D%5Cmathbf%7BV%7D%29+%3D+%5Ctext%7Btr%7D%28%5Cmathbf%7BX%7D%27%5Cmathbf%7BX%7D%5Cmathbf%7BV%7D%5Cmathbf%7BV%7D%27%29+%5Cleq+%5Csum_%7Bi%3D1%7D%5Ek+%5Clambda_i%28%5Cmathbf%7BX%7D%27%5Cmathbf%7BX%7D%29+%5Clambda_i%28%5Cmathbf%7BV%7D%5Cmathbf%7BV%7D%27%29&bg=ffffff&fg=111111&s=0&c=20201002)
where the last inequality is known as von Neumann’s trace inequality, and the notation  ,
,  , represents the eigenvalues of a matrix arranged in order of decreasing size. We see that the sum of the variances of the columns of the principal components matrix attains the upper bound in von Neumann’s inequality when is the orthonormal matrix of eigenvectors of
, represents the eigenvalues of a matrix arranged in order of decreasing size. We see that the sum of the variances of the columns of the principal components matrix attains the upper bound in von Neumann’s inequality when is the orthonormal matrix of eigenvectors of  , so that
, so that  and
and
![\text{tr}[(\mathbf{X} \mathbf{V})' (\mathbf{X} \mathbf{V})] = \sum_{i=1}^k \lambda_i(\mathbf{X}'\mathbf{X})](https://s0.wp.com/latex.php?latex=%5Ctext%7Btr%7D%5B%28%5Cmathbf%7BX%7D+%5Cmathbf%7BV%7D%29%27+%28%5Cmathbf%7BX%7D+%5Cmathbf%7BV%7D%29%5D+%3D+%5Csum_%7Bi%3D1%7D%5Ek+%5Clambda_i%28%5Cmathbf%7BX%7D%27%5Cmathbf%7BX%7D%29&bg=ffffff&fg=111111&s=0&c=20201002)
There is a more general decomposition of the data matrix , called Singular Value Decomposition (SVD), which is closely related to PCA. The SVD approach is based on factoring into three parts

where  is an orthogonal
is an orthogonal  matrix containing the eigenvectors of the matrix
matrix containing the eigenvectors of the matrix  ,
,  is an diagonal matrix whose nonzero entries are called the singular values of and are the square roots of the eigenvalues of , and is the orthogonal matrix of eigenvectors of . Note that is an matrix but with the same eigenvalues as , so is of rank . Thus, there will be columns of containing the eigenvectors of and the rest of the columns will have to be ‘padded’ with unit vectors that are pairwise orthogonal with all the others (e.g., these added columns can each have a 1 as the only nonzero element, with the positions of the 1 varied to ensure orthogonality with the other columns of ). The matrix will typically have rows of zeros below the diagonal upper part.
is an diagonal matrix whose nonzero entries are called the singular values of and are the square roots of the eigenvalues of , and is the orthogonal matrix of eigenvectors of . Note that is an matrix but with the same eigenvalues as , so is of rank . Thus, there will be columns of containing the eigenvectors of and the rest of the columns will have to be ‘padded’ with unit vectors that are pairwise orthogonal with all the others (e.g., these added columns can each have a 1 as the only nonzero element, with the positions of the 1 varied to ensure orthogonality with the other columns of ). The matrix will typically have rows of zeros below the diagonal upper part.
The decomposition in (4) is used widely in data analysis and image compression. For example, in the case of image compression, might be an extremely large matrix containing information about each pixel in an image. The factorisation on the right-hand side of (4) can then be used to reduce the dimensionality of the data in a manner reminiscent of PCA. It may be possible to limit the nonzero singular values in to a much smaller number than , and to use only the corresponding first few columns of , while still retaining most of the key information required to render the image faithfully. Also note that in the case when is a real square matrix, the right-hand side of (4) can be interpreted in geometric terms as decomposing the transformation represented by the matrix into a rotation, followed by a scaling, followed by another rotation.
It is useful to understand the link between SVD and PCA because computational maths systems like Python and MATLAB have in-built functions for SVD which can be used to speed up the calculations required for PCA. Given a data matrix , the SVD in (4) can be carried out quickly and easily using in-built functions. The output matrices and can then be used to construct the principal components matrix and eigenvalue matrix required for PCA.