I recently needed to approximate a logarithm of the form 




Therefore, suppose we replace 



![= \int_1^x dy \big(y^{\frac{1}{n}-1}\big) = \bigg[\frac{1}{(1/n)}y^{1/n}\bigg]_1^x](https://s0.wp.com/latex.php?latex=%3D+%5Cint_1%5Ex+dy+%5Cbig%28y%5E%7B%5Cfrac%7B1%7D%7Bn%7D-1%7D%5Cbig%29+%3D+%5Cbigg%5B%5Cfrac%7B1%7D%7B%281%2Fn%29%7Dy%5E%7B1%2Fn%7D%5Cbigg%5D_1%5Ex&bg=ffffff&fg=111111&s=0&c=20201002)

The approximation formula 




A mathematics and physics `scrapbook', with notes on miscellaneous things that catch my interest in a range of areas including: mathematical methods; number theory; probability theory; stochastic processes; mathematical economics; econometrics; quantum theory; relativity theory; cosmology; cloud physics; statistical mechanics; nonlinear dynamics; electronic engineering; graph and network theory; mathematics in Latin; computational mathematics using Python and other maths software.
I recently needed to approximate a logarithm of the form
Therefore, suppose we replace
The approximation formula
Zipf’s law refers to the phenomenon that many data sets in social and exact sciences are observed to obey a power law of the form 

The simple process discussed here involves the appearance of new species within families of closely related species called genera. New species appear within genera (through evolutionary processes) which usually remain quite close in their main characteristics to the pre-existing species. However, every so often, a new species will appear which is sufficiently different from all pre-existing ones to enable it to be regarded as having started a completely new genus. We can construct a simple Yule-Simon process as a stylised version of this. Suppose that species appear one at a time and that when the number of species reaches 




We further assume that between each genus and the next, the 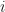
where 

Let 


Now, when these genera gain the new species, they will move out of the class of genera with 


When these genera gain a new species, they will move into the class of genera with 


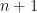
However, this master equation does not hold for genera of size 1. Instead, these genera obey
The second term on the right-hand side is 1 because, by definition, exactly one new genus appears at each step of the process, so there is only one entrant from the class of genera with zero species into the class of genera with one species.
We assume there is a steady state as 
and the steady state equation for

But using the steady state equation for 
and substituting this back into the steady state equation for
Continuing the iteration in this way we get
and using the steady state expression for 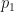
Since 

Now, the gamma function is defined as

and the beta function 


It is not too difficult to show that the two are related by the equation
and furthermore, for large 
Comparing with the final expression for

So we get a power law when the genera size
When the parameters of some physical systems are precisely tuned, the systems can enter a phase transition in which the behaviour of observables changes dramatically. In particular, the systems can become scale-free in the sense of losing any relationship to scales of measurement, i.e., the systems suddenly switch to behaving the same irrespective of the scales of measurement being used. (For many examples of this, and a discussion of scale invariance arising from phase transitions, visit this website). Among the critical phenomena in the vicinity of these phase transitions we can then get power law behaviours, e.g., for probability distributions of observables in the system. In the present note, I want to record a simple proof that whenever a probability distribution 
The scale-free characteristic can be expressed as
so that multiplying the argument by a scale factor 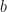


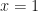

so the expression for 
Since this is an identity in the scale factor
Setting 
This is a separable first-order differential equation, so
and therefore
Setting 
and thus we arrive at the power law
where
So the power law distribution 
When you think of the classical harmonic oscillator, think of a mass connected to a spring oscillating at a natural frequency which is independent of the initial position or velocity of the mass. The natural frequency will depend only on the stiffness of the spring and the size of the mass.
When you think of the quantum harmonic oscillator, think of quasi-factorising the Hamiltonian operator in Schrödinger’s equation to get creation and annihilation operators, re-expressing the Hamiltonian in terms of these ladder operators, and operating on the system with these ladder operators to increase and decrease the energy of the system by multiples of discrete packets of energy (‘quanta’).
Recall that the classical harmonic oscillator model, say a mass 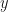


Defining 
which has the general solution

We can obtain particular solutions from this general solution by specifying initial conditions. For example, starting off with the mass
Applying these to the general solution we get the equations
Therefore the particular solution for this situation is
The work done by the spring force on the mass in opposing its motion from, say, the equilibrium position to a height
This work can be viewed as transferring energy from the kinetic energy of the mass to the elastic potential energy of the spring (or more strictly speaking, the mass-spring system). The potential energy of the spring for this displacement from equilibrium is thus
(Also note that, as usual, the original spring force is recoverable as the negative of the first derivative of the potential energy).
If the maximum displacement of the spring before returning to equilibrium is 


This maximum speed is higher the higher the spring constant
In the case of the quantum harmonic oscillator, we use the time-independent Schrödinger equation rather than Newton’s second law to get the relevant differential equation. Starting from the total energy equation
where 


The bracketed expression on the left-hand side is the Hamiltonian operator 
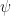
Inside the brackets we now have an operator sum of squares similar to the algebraic sum of squares 



However, multiplying out this expression does not give us 
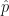

![= \hat{H} + \frac{i \omega}{2}[\hat{x}, \hat{p}]](https://s0.wp.com/latex.php?latex=%3D+%5Chat%7BH%7D+%2B+%5Cfrac%7Bi+%5Comega%7D%7B2%7D%5B%5Chat%7Bx%7D%2C+%5Chat%7Bp%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)
where
![[\hat{x}, \hat{p}] \equiv \hat{x}\hat{p} - \hat{p} \hat{x} = i \hbar](https://s0.wp.com/latex.php?latex=%5B%5Chat%7Bx%7D%2C+%5Chat%7Bp%7D%5D+%5Cequiv+%5Chat%7Bx%7D%5Chat%7Bp%7D+-+%5Chat%7Bp%7D+%5Chat%7Bx%7D+%3D+i+%5Chbar&bg=ffffff&fg=111111&s=0&c=20201002)
is the quantum mechanical commutator of
where 

If we reversed the order of
We can therefore write the Schrödinger equation 
However, the real usefulness of ladder operators becomes apparent when we apply the Hamiltonian written in this form to 
Therefore if 
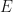
Using the same algebra, we find that if 

We therefore call the ladder operator 

Now, the Schrödinger equation 
for 






Normalizing, we get
so the explicit form of the zero point energy eigenfunction is
We can now get all the higher energy eigenfunctions by repeatedly applying the raising operator
In the present note I want to explore the decomposition of an arbitrary Lorentz transformation 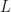





Any 

where 




Therefore 
The set of all Lorentz matrices thus defined form a group, the Lorentz group, under matrix multiplication. The identity element of the group is obviously the 
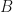
so the product is also Lorentz. To prove that the inverse of a Lorentz matrix is also Lorentz, suppose 
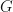
so the inverse of 


so the inverse of
For two inertial reference frames in standard configuration, the Lorentz transformation will be a
such that 
Notice that since 
which is itself a simple Lorentz matrix corresponding to a reversal in the sign of 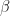
Notice also that the transpose of a Lorentz matrix is Lorentz. To see this, if 



as required.
We now look in detail at the decomposition result mentioned at the start of this note. This expresses in mathematical terms the possibility of simplifying an arbitrary Lorentz matrix by a suitable rotation of axes. The result says that an arbitrary Lorentz matrix 
where 


and
where 





![[r \ s \ t]](https://s0.wp.com/latex.php?latex=%5Br+%5C++s++%5C+t%5D&bg=ffffff&fg=111111&s=0&c=20201002)

A corollary of this result is that if
To prove this decomposition result and its corollary, we begin by observing that
But from the first element of the product 
we get
Using this result in the expression for 
Therefore the matrix
is orthogonal (i.e., its columns and rows are orthogonal unit vectors – recall that
Therefore
This is a 

using the fact that 

as claimed in the decomposition result above.
Now, since 

where the omitted rows are of the same form as the first row, but with 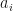

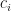






We now focus on proving that the top row and first column of this product are 

The 
(since 



(since this is the same quadratic form as in the first element of
The next element in the top row is
(since 
For the third element in the top row we have
since
Finally, for the fourth element in the top row we have
since
Next, we consider the first column of the product. For each
since the quadratic form inside the bracket is zero when 
Therefore the product matrix is of the form
where the 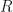
To prove the corollary, note that in a simple Lorentz matrix the relative velocity is given by
and in
An apparent paradox in Einstein’s Special Theory of Relativity, known as a Thomas precession rotation in atomic physics, has been verified experimentally in a number of ways. However, somewhat surprisingly, it has not yet been demonstrated algebraically in a straightforward manner using Lorentz-matrix-algebra. Authors in the past have resorted instead to computer verifications, or to overly-complicated derivations, leaving undergraduate students in particular with the impression that this is a mysterious and mathematically inaccessible phenomenon. This is surprising because, as shown in the present note, it is possible to use a basic property of orthogonal Lorentz matrices and a judicious choice for the configuration of the relevant inertial frames to give a very transparent algebraic proof. It is pedagogically useful for physics students particularly at undergraduate level to explore this. It not only clarifies the nature of the paradox at an accessible mathematical level and sheds additional light on some mathematical properties of Lorentz matrices and relatively-moving frames. It also illustrates the satisfaction that a clear mathematical understanding of a physics problem can bring, compared to uninspired computations or tortured derivations.
My full paper can be found on ArXiv.org.
B-splines and collocation techniques have been applied to the solution of Schrödinger’s equation in quantum mechanics since the early 1970s, but one aspect that is noticeably missing from this literature is the use of Gaussian points (i.e., the zeros of Legendre polynomials) as the collocation points, which can significantly reduce approximation errors. Authors in the past have used equally spaced or nonlinearly distributed collocation points (noticing that the latter can increase approximation accuracy) but, strangely, have continued to avoid Gaussian collocation points so there are no published papers employing this approach. Using the methodology and computer routines provided by Carl de Boor’s book A Practical Guide to Splines as a `numerical laboratory’, the present dissertation examines how the use of Gaussian collocation points can interact with other features such as box size, mesh size and the order of polynomial approximants to affect the accuracy of approximations to Schrödinger’s bound state wave functions for the electron in the hydrogen atom. In particular, we explore whether or not, and under what circumstances, B-spline collocation at Gaussian points can produce more accurate approximations to Schrödinger’s wave functions than equally spaced and nonlinearly distributed collocation points. We also apply B-spline collocation at Gaussian points to a Schrödinger equation with cubic nonlinearity which has been used extensively in the past to study nonlinear phenomena. Our computer experiments show that in the case of the hydrogen atom, collocation at Gaussian points can be a highly successful approach, consistently superior to equally spaced collocation points and often superior to nonlinearly distributed collocation points. However, we do encounter some situations, typically when the mesh is quite coarse relative to the box size for the hydrogen atom, and also in the cubic Schrödinger equation case, in which nonlinearly distributed collocation points perform significantly better than Gaussian collocation points.
Full dissertation can be found on ArXiv.org.
A Lie group is a group which is also a smooth differentiable manifold. Every Lie group has an associated tangent space called a Lie algebra. As a vector space, the Lie algebra is often easier to study than the associated Lie group and can reveal most of what we need to know about the group. This is one of the general motivations for Lie theory. A table of some common Lie groups and their associated Lie algebras can be found here. All matrix groups are Lie groups. An example of a matrix Lie group is the 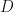



The link between 
In the rest of this note I will unpack some aspects of the above brief summary without going too much into highly technical details. The Lie theory of rotations is based on a simple symmetry/invariance consideration, namely that rotations leave the scalar products of vectors invariant. In particular, they leave the lengths of vectors invariant. The Lie theory approach is much more easily generalisable to higher dimensions than the elementary trigonometric approach using the familiar rotation matrices in two and three dimensions. Instead of obtaining the familiar trigonometric rotation matrices by analysing the trigonometric effects of rotations, we will see below that they arise in Lie theory from the exponential map linking the Lie algebra 
Begin by considering rotations in 




Since we require lengths to remain unchanged after rotation, we have
which implies
In other words, the matrix
Therefore we must have
But we can exclude the case 
has determinant 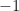

It is straightforward to verify that 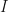

The fact that 








If we now Taylor-expand 
where 

Thus, the matrix 


To clarify this, we will consider the antisymmetric basis matrices for 







In the case 
Finally, in the case 
So in the case of a general infinitesimal rotation in 
But note that using the standard matrix exponential series we have
This suggests
and in fact this relationship between rotations and the exponentials of antisymmetric matrices turns out to be exact, not just an approximation. To see this, observe that 

(note that in matrix exponentiation 
Thus, 

so
So we have a tight link between 


which indicates that the antisymmetric basis matrices 
where the single real number 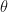
To further elucidate how the antisymmetric basis matrices
This shows that the commutator of two antisymmetric matrices is itself antisymmetric, so the commutator can be written as a linear combination of the antisymmetric basis matrices 

so every commutator between antisymmetric matrices can be written in terms of the commutators ![[J_{(mn)}, J_{(pq)}]](https://s0.wp.com/latex.php?latex=%5BJ_%7B%28mn%29%7D%2C+J_%7B%28pq%29%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)

where 
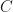
For the right-hand side we get
Equating the two expansions we get
where the remaining terms on the right-hand side are of second and higher order in
This shows that 
Since every commutator between antisymmetric matrices can be written in terms of the commutators
completely characterises the Lie algebra
for the 
Focus on 

Now focus on 
So the element in the
But notice that
and similarly for the other Einstein summation terms. Thus, the above sum reduces to
But
Thus the element in the
Extending this to the matrix as a whole gives the required formula:
Certain arithmetical functions, known as Dirichlet characters mod 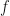





which are incongruent modulo 
![[a]_k](https://s0.wp.com/latex.php?latex=%5Ba%5D_k&bg=ffffff&fg=111111&s=0&c=20201002)




![[1]_{12} = \{1, 13, 25, \ldots\}](https://s0.wp.com/latex.php?latex=%5B1%5D_%7B12%7D+%3D+%5C%7B1%2C+13%2C+25%2C+%5Cldots%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002)
What we are saying is that this set ![\{[1]_{12}, [5]_{12}, [7]_{12}, [11]_{12}\}](https://s0.wp.com/latex.php?latex=%5C%7B%5B1%5D_%7B12%7D%2C+%5B5%5D_%7B12%7D%2C+%5B7%5D_%7B12%7D%2C+%5B11%5D_%7B12%7D%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002)
(i.e., the product of the residue classes of 
![[1]_k](https://s0.wp.com/latex.php?latex=%5B1%5D_k&bg=ffffff&fg=111111&s=0&c=20201002)
![[b]_k](https://s0.wp.com/latex.php?latex=%5Bb%5D_k&bg=ffffff&fg=111111&s=0&c=20201002)

There are 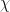





These facts uniquely determine the Dirichlet character table for each
k = 2

We have 


k = 3
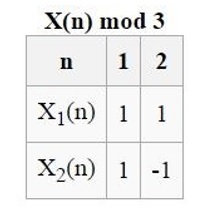
We have 


and
Note that the set of least positive residues mod 
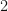


Therefore the non-principal Dirichlet character will be completely determined by the values of 
then
(though this calculation is superfluous here since 

k = 4

We have 

and
Note that the set of least positive residues mod 


Therefore the non-principal Dirichlet character will be completely determined by the values of 
then
(though again this second calculation is superfluous since
k = 5

We have 
Note that the set of least positive residues mod 



Therefore the non-principal Dirichlet characters will be completely determined by the values of
then
(and we have
To compute the third character we can set
then
(and we have 
To compute the fourth character we set
then
(and we have 
k = 6

We have 
and
Note that the set of least positive residues mod 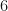


Therefore the non-principal Dirichlet character will be completely determined by the values of 
then
(though again this second calculation is superfluous since
k = 7
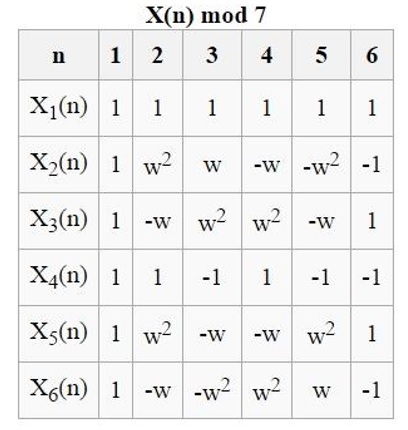
We have 
Note that the set of least positive residues mod 





Therefore the non-principal Dirichlet characters will be completely determined by the values of
then
(and we have
To compute the third character we can set
then
(and we have
To compute the fourth character we can set
then
(and we have
To compute the fifth character we can set
then
(and we have 
Finally, to compute the sixth character we set
then
(and we have 
k = 8

We have 
In this case, none of the four elements of the set of least positive residues mod 
Each character’s values must be chosen in such a way that these three relations hold.
To compute the second character, suppose we begin by trying to set
and
Then we must have
but then
so this does not work. If instead we try to set
then we must have
but then
so this does not work either. Computations like these show that 


To compute the second character we can set
and
then we must have
and this works.
To compute the third character we can set
and
then we must have
and this works too.
Finally, to compute the fourth character we can set
and
then we must have
and this works too.
k = 9

We have 
Note that the set of least positive residues mod 




Therefore the non-principal Dirichlet characters will be completely determined by the values of
then
(and we have
To compute the third character we can set
then
(and we have
To compute the fourth character we can set
then
(and we have
To compute the fifth character we can set
then
(and we have
Finally, to compute the sixth character we can set
then
(and we have
k = 10

We have 
Note that the set of least positive residues mod 



Therefore the non-principal Dirichlet characters will be completely determined by the values of
then
(and we have
To compute the third character we can set
then
(and we have
Finally, to compute the fourth character we set
then
(and we have
k = 11

We have 
Note that the set of least positive residues mod 







Therefore the non-principal Dirichlet characters will be completely determined by the values of
then
(and we have
To compute the third character we can set
then
(and we have
To compute the fourth character we can set
then
(and we have
To compute the fifth character we can set
then
(and we have
To compute the sixth character we can set
then
(and we have
To compute the seventh character we can set
then
(and we have 
To compute the eighth character we can set
then
(and we have 
To compute the ninth character we can set
then
(and we have 
Finally, to compute the tenth character we set
then
(and we have 
In a previous note I studied the mathematical setup of Noether’s Theorem and its proof. I briefly illustrated the mathematical machinery by considering invariance under translations in time, giving the law of conservation of energy, and invariance under translations in space, giving the law of conservation of linear momentum. I briefly mentioned that invariance under rotations in space would also yield the law of conservation of angular momentum but I did not work this out explicitly. I want to quickly do this in the present note.
We imagine a particle of unit mass moving freely in the absence of any potential field, and tracing out a path 



where 
In terms of Lagrangian mechanics, the path
(in the absence of a potential field the total energy consists only of kinetic energy).
Now imagine that the entire path
which reduces to the identity when 
and therefore
so the action functional is invariant under this rotation since
Therefore Noether’s theorem applies. Let
Then Noether’s theorem in this case says
where
We have
Therefore Noether’s theorem gives us (remembering 
The expression on the left-hand side of this equation is the angular momentum of the particle (cf. the brief discussion of angular momentum at the start of this note), so this result is precisely the statement that the angular momentum is conserved. Noether’s theorem shows us that this is a direct consequence of the invariance of the action functional of the particle under rotations in space.



![(n+1)p_{k,n+1} = np_{k,n} + \frac{m}{m+1}[(k-1)p_{k-1,n} - kp_{k,n}]](https://s0.wp.com/latex.php?latex=%28n%2B1%29p_%7Bk%2Cn%2B1%7D+%3D+np_%7Bk%2Cn%7D+%2B+%5Cfrac%7Bm%7D%7Bm%2B1%7D%5B%28k-1%29p_%7Bk-1%2Cn%7D+-+kp_%7Bk%2Cn%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)

![(n+1)p_{k} = np_{k} + \frac{m}{m+1}[(k-1)p_{k-1} - kp_{k}]](https://s0.wp.com/latex.php?latex=%28n%2B1%29p_%7Bk%7D+%3D+np_%7Bk%7D+%2B+%5Cfrac%7Bm%7D%7Bm%2B1%7D%5B%28k-1%29p_%7Bk-1%7D+-+kp_%7Bk%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)







































































![R_2 = [e_1 \ r^{\prime} \ s^{\prime} \ t^{\prime}]^T](https://s0.wp.com/latex.php?latex=R_2+%3D+%5Be_1+%5C+r%5E%7B%5Cprime%7D+%5C+s%5E%7B%5Cprime%7D++%5C+t%5E%7B%5Cprime%7D%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002)




![[a^0_0 \ -a^0_1 \ -a^0_2 \ -a^0_3] \begin{bmatrix} a^0_0 \\ -a^0_1 \\ -a^0_2 \\ -a^0_3 \end{bmatrix} = 1](https://s0.wp.com/latex.php?latex=%5Ba%5E0_0+%5C+-a%5E0_1+%5C+-a%5E0_2%C2%A0+%5C+-a%5E0_3%5D+%5Cbegin%7Bbmatrix%7D%C2%A0a%5E0_0+%5C%5C+-a%5E0_1+%5C%5C+-a%5E0_2+%5C%5C+-a%5E0_3+%5Cend%7Bbmatrix%7D+%3D+1&bg=ffffff&fg=111111&s=0&c=20201002)


![[r \ s \ t] = \begin{bmatrix} r_1 & s_1 & t_1 \\ r_2 & s_2 & t_2 \\ r_3 & s_3 & t_3 \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Br+%5C+s+%5C+t%5D+%3D+%5Cbegin%7Bbmatrix%7D+r_1+%26+s_1+%26+t_1+%5C%5C%C2%A0r_2+%26+s_2+%26+t_2+%5C%5C%C2%A0r_3+%26+s_3+%26+t_3+%5Cend%7Bbmatrix%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![R_2 = [e_1 \ r^{\prime} \ s^{\prime} \ t^{\prime}]^T = \begin{bmatrix} e_1 \\ r^{\prime} \\ s^{\prime} \\ t^{\prime} \end{bmatrix} = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & r_1 & r_2 & r_3 \\ 0 & s_1 & s_2 & s_3 \\ 0 & t_1 & t_2 & t_3 \end{bmatrix}](https://s0.wp.com/latex.php?latex=R_2+%3D+%5Be_1+%5C+r%5E%7B%5Cprime%7D+%5C+s%5E%7B%5Cprime%7D+%5C+t%5E%7B%5Cprime%7D%5D%5ET+%3D+%5Cbegin%7Bbmatrix%7D+e_1+%5C%5C+r%5E%7B%5Cprime%7D+%5C%5C+s%5E%7B%5Cprime%7D+%5C%5C+t%5E%7B%5Cprime%7D+%5Cend%7Bbmatrix%7D+%3D+%5Cbegin%7Bbmatrix%7D+1+%26+0+%26+0+%26+0+%5C%5C+0+%26+r_1+%26+r_2+%26+r_3+%5C%5C%C2%A0%C2%A00+%26%C2%A0s_1+%26+s_2+%26+s_3+%5C%5C%C2%A00+%26+t_1+%26+t_2+%26+t_3+%5Cend%7Bbmatrix%7D&bg=ffffff&fg=111111&s=0&c=20201002)




















![[J_{(mn)}, J_{(pq)}] = \delta_{np}J_{(mq)} + \delta_{mq}J_{(np)} - \delta_{mp}J_{(nq)} - \delta_{nq}J_{(mp)}](https://s0.wp.com/latex.php?latex=%5BJ_%7B%28mn%29%7D%2C+J_%7B%28pq%29%7D%5D+%3D+%5Cdelta_%7Bnp%7DJ_%7B%28mq%29%7D+%2B+%5Cdelta_%7Bmq%7DJ_%7B%28np%29%7D+-+%5Cdelta_%7Bmp%7DJ_%7B%28nq%29%7D+-+%5Cdelta_%7Bnq%7DJ_%7B%28mp%29%7D&bg=ffffff&fg=111111&s=0&c=20201002)






























![([A, B])^{\ T} = (AB - BA)^{\ T} = (AB)^{\ T} - (BA)^{\ T}](https://s0.wp.com/latex.php?latex=%28%5BA%2C+B%5D%29%5E%7B%5C+T%7D+%3D+%28AB+-+BA%29%5E%7B%5C+T%7D+%3D+%28AB%29%5E%7B%5C+T%7D+-+%28BA%29%5E%7B%5C+T%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![= B^{\ T} A^{\ T} - A^{\ T} B^{\ T} = BA - AB = - [A, B]](https://s0.wp.com/latex.php?latex=%3D+B%5E%7B%5C+T%7D+A%5E%7B%5C+T%7D%C2%A0+-+A%5E%7B%5C+T%7D%C2%A0B%5E%7B%5C+T%7D%C2%A0%3D+BA+-+AB+%3D+-+%5BA%2C+B%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![[A, B] = \sum_{m, n, p, q} \theta_{(mn)} \theta_{(pq)}^{\ \prime}[J_{(mn)}, J_{(pq)}]](https://s0.wp.com/latex.php?latex=%5BA%2C+B%5D+%3D+%5Csum_%7Bm%2C+n%2C+p%2C+q%7D+%5Ctheta_%7B%28mn%29%7D+%5Ctheta_%7B%28pq%29%7D%5E%7B%5C+%5Cprime%7D%5BJ_%7B%28mn%29%7D%2C+J_%7B%28pq%29%7D%5D&bg=ffffff&fg=111111&s=0&c=20201002)



![= I + A + B + \frac{1}{2}(A^2 + AB + BA + B^2) + \frac{1}{2}[A, B] + \cdots](https://s0.wp.com/latex.php?latex=%3D+I+%2B+A+%2B+B+%2B+%5Cfrac%7B1%7D%7B2%7D%28A%5E2+%2B+AB+%2B+BA+%2B+B%5E2%29+%2B+%5Cfrac%7B1%7D%7B2%7D%5BA%2C+B%5D+%2B+%5Ccdots&bg=ffffff&fg=111111&s=0&c=20201002)
![= I + A + B + \frac{1}{2}(A + B)^2 + \frac{1}{2}[A, B] + \cdots](https://s0.wp.com/latex.php?latex=%3D+I+%2B+A+%2B+B+%2B+%5Cfrac%7B1%7D%7B2%7D%28A+%2B+B%29%5E2+%2B+%5Cfrac%7B1%7D%7B2%7D%5BA%2C+B%5D+%2B+%5Ccdots&bg=ffffff&fg=111111&s=0&c=20201002)
![= I + A + B + \frac{1}{2}[A, B] + \cdots](https://s0.wp.com/latex.php?latex=%3D+I+%2B+A+%2B+B+%2B%C2%A0%5Cfrac%7B1%7D%7B2%7D%5BA%2C+B%5D+%2B+%5Ccdots&bg=ffffff&fg=111111&s=0&c=20201002)

![C = A + B + \frac{1}{2}[A, B] + \cdots](https://s0.wp.com/latex.php?latex=C+%3D+A+%2B+B+%2B%C2%A0%5Cfrac%7B1%7D%7B2%7D%5BA%2C+B%5D+%2B+%5Ccdots&bg=ffffff&fg=111111&s=0&c=20201002)
![C = A + B + \frac{1}{2}[A, B]](https://s0.wp.com/latex.php?latex=C+%3D+A+%2B+B+%2B+%5Cfrac%7B1%7D%7B2%7D%5BA%2C+B%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![+ \frac{1}{12}\big([A, [A, B]] + [B, [B, A]]\big)](https://s0.wp.com/latex.php?latex=%2B+%5Cfrac%7B1%7D%7B12%7D%5Cbig%28%5BA%2C+%5BA%2C+B%5D%5D+%2B+%5BB%2C+%5BB%2C+A%5D%5D%5Cbig%29&bg=ffffff&fg=111111&s=0&c=20201002)
![- \frac{1}{24}[B, [A, [A, B]]]](https://s0.wp.com/latex.php?latex=-+%5Cfrac%7B1%7D%7B24%7D%5BB%2C+%5BA%2C+%5BA%2C+B%5D%5D%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![- \frac{1}{720}\big([B, [B, [B, [B, A]]]] + [A, [A, [A, [A, B]]]]\big) + \cdots](https://s0.wp.com/latex.php?latex=-+%5Cfrac%7B1%7D%7B720%7D%5Cbig%28%5BB%2C+%5BB%2C+%5BB%2C+%5BB%2C+A%5D%5D%5D%5D+%2B+%5BA%2C+%5BA%2C+%5BA%2C+%5BA%2C+B%5D%5D%5D%5D%5Cbig%29+%2B+%5Ccdots&bg=ffffff&fg=111111&s=0&c=20201002)
![[J_{(mn)}, J_{(pq)}] = J_{(mn)} J_{(pq)} - J_{(pq)} J_{(mn)}](https://s0.wp.com/latex.php?latex=%5BJ_%7B%28mn%29%7D%2C+J_%7B%28pq%29%7D%5D+%3D+J_%7B%28mn%29%7D+J_%7B%28pq%29%7D+-%C2%A0J_%7B%28pq%29%7D+J_%7B%28mn%29%7D&bg=ffffff&fg=111111&s=0&c=20201002)

















![[5]_{12} = \{5, 17, 29, \ldots\}](https://s0.wp.com/latex.php?latex=%5B5%5D_%7B12%7D+%3D+%5C%7B5%2C+17%2C+29%2C+%5Cldots%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![[7]_{12} = \{7, 19, 31, \ldots\}](https://s0.wp.com/latex.php?latex=%5B7%5D_%7B12%7D+%3D+%5C%7B7%2C+19%2C+31%2C+%5Cldots%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![[11]_{12} = \{11, 23, 35, \ldots\}](https://s0.wp.com/latex.php?latex=%5B11%5D_%7B12%7D+%3D+%5C%7B11%2C+23%2C+35%2C+%5Cldots%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![[a]_k \cdot [b]_k = [ab]_k](https://s0.wp.com/latex.php?latex=%5Ba%5D_k+%5Ccdot+%5Bb%5D_k+%3D+%5Bab%5D_k&bg=ffffff&fg=111111&s=0&c=20201002)
![\chi(n) = \left \{ \begin{array}{c c} f([n]_k) & \text{if } gcd(n, k) = 1\\ 0 & \ \text{if } gcd(n, k) > 1 \end{array} \right.](https://s0.wp.com/latex.php?latex=%5Cchi%28n%29+%3D+%5Cleft+%5C%7B+%5Cbegin%7Barray%7D%7Bc+c%7D+f%28%5Bn%5D_k%29+%26+%5Ctext%7Bif+%7D+gcd%28n%2C+k%29+%3D+1%5C%5C+0+%26+%5C+%5Ctext%7Bif+%7D+gcd%28n%2C+k%29+%3E+1+%5Cend%7Barray%7D+%5Cright.&bg=ffffff&fg=111111&s=0&c=20201002)







































































































































































































![S[\gamma(t)] = \int_{t_1}^{t_2} dt \frac{1}{2}(\dot{x}^2 + \dot{y}^2)](https://s0.wp.com/latex.php?latex=S%5B%5Cgamma%28t%29%5D+%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+dt+%5Cfrac%7B1%7D%7B2%7D%28%5Cdot%7Bx%7D%5E2+%2B+%5Cdot%7By%7D%5E2%29&bg=ffffff&fg=111111&s=0&c=20201002)







![S[\overline{\gamma}(t)] = \int_{t_1}^{t_2} d\overline{t} \frac{1}{2}(d\dot{\overline{x}}^2 + d\dot{\overline{y}}^2) = \int_{t_1}^{t_2} dt \frac{1}{2}(\dot{x}^2 + \dot{y}^2) = S[\gamma(t)]](https://s0.wp.com/latex.php?latex=S%5B%5Coverline%7B%5Cgamma%7D%28t%29%5D+%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+d%5Coverline%7Bt%7D+%5Cfrac%7B1%7D%7B2%7D%28d%5Cdot%7B%5Coverline%7Bx%7D%7D%5E2+%2B%C2%A0d%5Cdot%7B%5Coverline%7By%7D%7D%5E2%29+%3D%C2%A0%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+dt+%5Cfrac%7B1%7D%7B2%7D%28%5Cdot%7Bx%7D%5E2+%2B+%5Cdot%7By%7D%5E2%29+%3D+S%5B%5Cgamma%28t%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)








