In this note I want to explore some of the details involved in the close analogy between:
A). the way Cantor constructed the real number field as the completion of the rationals using Cauchy sequences with the usual Euclidean metric; and
B). the way the p-adic number field can be similarly constructed as the completion of the rationals, but using Cauchy sequences with a different metric (known as an ultrametric).
I have found that exploring this analogy in some detail has allowed me to get quite a good foothold on some of the key features of p-adic analysis.
- A basic initial characterisation of p-adic numbers
A lot flows from the basic observation that given a prime number  and a rational number
and a rational number  , it is always possible to factor out the powers of in
, it is always possible to factor out the powers of in  as in the equation
as in the equation

with

The exponent  , known as the p-adic valuation in the literature, can be negative, zero or positive depending on how the prime appears (or not) as a factor in the numerator and denominator of the rational number .
, known as the p-adic valuation in the literature, can be negative, zero or positive depending on how the prime appears (or not) as a factor in the numerator and denominator of the rational number .
For example, suppose we specify the prime  . Then we can factor out the powers of
. Then we can factor out the powers of  in the rational numbers
in the rational numbers  ,
,  , and
, and  as
as



respectively.
For each prime number , we can write any positive rational number in the power series form

where is the p-adic valuation of and the coefficients  come from the set of least positive residues of . (These coefficients will always exhibit a repeating pattern in the power series of a rational number). This power series form is called the p-adic expansion of . In the case
come from the set of least positive residues of . (These coefficients will always exhibit a repeating pattern in the power series of a rational number). This power series form is called the p-adic expansion of . In the case  , i.e., when is a positive integer, the p-adic expansion is just the expansion of in base .
, i.e., when is a positive integer, the p-adic expansion is just the expansion of in base .
If the rational number is negative rather than positive, its p-adic expansion can be obtained from the positive version above as

where

and

for  .
.
We can obtain the p-adic expansion for any rational number by the following algorithm. Let the p-adic expansion we want to find be



where all fractions are always given in their lowest terms. We deduce that the p-adic expansion of  is then
is then

so, since the right hand side equals  mod , we can compute as
mod , we can compute as
 (mod )
(mod )
Next, we see that



We deduce that the p-adic expansion of  is then
is then

so, since the right hand side equals  mod , we can compute as
mod , we can compute as
 (mod )
(mod )
We continue this process until the repeating pattern in the coefficients is spotted.
For example, suppose we specify the prime to be  and consider the rational number
and consider the rational number  . The p-adic valuation of this rational number is
. The p-adic valuation of this rational number is 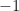 since we can write
since we can write

Therefore we expect the p-adic expansion for to have  in its first term. Following the steps of the algorithm we compute the first coefficient as
in its first term. Following the steps of the algorithm we compute the first coefficient as
 (mod
(mod  )
)
Then we have

so we can compute the second coefficient as
 (mod )
(mod )
Then we have

so we can compute the third coefficient as
 (mod )
(mod )
Then we have

so we see immediately that the fourth coefficient will be the same as the second, and the pattern will repeat from this point onwards. Therefore we have obtained the p-adic expansion of as

It can be shown that the set of all p-adic expansions is an algebraic field. This is called the field of p-adic numbers and is usually denoted by  in the literature. In the rest of this note I will explore some aspects of the construction of the field by analogy with the way Cantor constructed the field of real numbers from the field of rationals. The next section reviews Cantor’s construction of the reals.
in the literature. In the rest of this note I will explore some aspects of the construction of the field by analogy with the way Cantor constructed the field of real numbers from the field of rationals. The next section reviews Cantor’s construction of the reals.
- Cantor’s construction of the real number field
In Cantor’s construction of the real numbers from the rationals, we regard the latter as a metric space  where the metric
where the metric 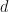 is defined in terms of the ordinary Euclidean absolute value function:
is defined in terms of the ordinary Euclidean absolute value function:

The central problem in constructing the real number field  from the field of rationals
from the field of rationals 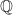 is that of defining irrational numbers only in terms of rationals. This can be done in alternative ways, e.g., using Dedekind cuts, but Cantor’s approach achieves it using the concept of a Cauchy sequence. A Cauchy sequence in a metric space is a sequence of points which become arbitrarily `close’ to each other with respect to the metric, as we move further and further out in the sequence. More formally, in the context of the metric space , a sequence
is that of defining irrational numbers only in terms of rationals. This can be done in alternative ways, e.g., using Dedekind cuts, but Cantor’s approach achieves it using the concept of a Cauchy sequence. A Cauchy sequence in a metric space is a sequence of points which become arbitrarily `close’ to each other with respect to the metric, as we move further and further out in the sequence. More formally, in the context of the metric space , a sequence  of rationals is a Cauchy sequence if for each
of rationals is a Cauchy sequence if for each  (where
(where  ) there is an
) there is an 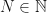 such that
such that
 for all
for all 
For example, if  , then we can be sure that there is a certain point in the Cauchy sequence beyond which all the terms of the sequence will always be within a millionth of each other in absolute value. If instead we set
, then we can be sure that there is a certain point in the Cauchy sequence beyond which all the terms of the sequence will always be within a millionth of each other in absolute value. If instead we set  , we might have to go further out in the sequence, but we can still be sure that beyond a certain point all the terms of the sequence from then on will be within a billionth of each other in absolute value. And so on.
, we might have to go further out in the sequence, but we can still be sure that beyond a certain point all the terms of the sequence from then on will be within a billionth of each other in absolute value. And so on.
Cantor’s approach to constructing the reals is based on the idea that any irrational number can be regarded as the limit of Cauchy sequences of rationals, so we can actually define the irrationals as sets of Cauchy sequences of rationals.
To illustrate, consider the irrational number 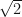 . Define three sequences of rationals
. Define three sequences of rationals  ,
,  ,
,  as follows:
as follows:


 for all
for all 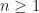 ,
,
 if
if  , otherwise
, otherwise  ,
,
 if , otherwise
if , otherwise  .
.
For each ,  lies between and
lies between and  , and at each iteration the closed interval
, and at each iteration the closed interval ![[a_n, b_n]](https://s0.wp.com/latex.php?latex=%5Ba_n%2C+b_n%5D&bg=ffffff&fg=111111&s=0&c=20201002) has length
has length

(To see this, note that from the definitions of the three sequences above we find that

so we get the result from this by a simple induction). Also, each closed interval contains . Therefore the closed interval is increasingly ‘closing in’ around , i.e., we have
![[a_{n+1}, b_{n+1}] \subseteq [a_n, b_n]](https://s0.wp.com/latex.php?latex=%5Ba_%7Bn%2B1%7D%2C+b_%7Bn%2B1%7D%5D+%5Csubseteq+%5Ba_n%2C+b_n%5D&bg=ffffff&fg=111111&s=0&c=20201002)
So for each of the sequences , , of rationals, the terms of the sequence are getting closer and closer to each other, and closer to . Cantor’s idea was basically to define an irrational such as to be the set containing all Cauchy sequences like , , and which converge to that irrational.
Formally, the process involves defining equivalence classes of Cauchy sequences in the metric space , so that two Cauchy sequences and belong to the same equivalence class, denoted  , if for each (where ) there is an such that
, if for each (where ) there is an such that
 for all
for all 
It is straightforward to show that  is an equivalence relation in the sense that it is reflexive (i.e.
is an equivalence relation in the sense that it is reflexive (i.e.  for all Cauchy sequences ), symmetric (i.e., if then
for all Cauchy sequences ), symmetric (i.e., if then  for all Cauchy sequences and ), and transitive (i.e., if and
for all Cauchy sequences and ), and transitive (i.e., if and  then
then  for all Cauchy sequences , and
for all Cauchy sequences , and  ).
).
Cantor defined a real number to be any equivalence class arising from , i.e., any set of the form

where is a Cauchy sequence in the metric space . Rational numbers are, of course, subsumed in this since any rational number  belongs to the (constant) Cauchy sequence defined by
belongs to the (constant) Cauchy sequence defined by  for all
for all  .
.
It is now possible to define all the standard relations and arithmetic operations on the real numbers constructed in this way, and it can also be shown that the set of reals constructed in this way is isomorphic to the set of reals defined by alternative means, such as Dedekind cuts.
The set of reals constructed in this way can be regarded as the completion of the set of rationals in the sense that it is obtained by adding to the set of rationals all the limits of all possible Cauchy sequences in which are irrational. In general, a metric space is said to be complete if every Cauchy sequence in that metric space converges to a point within that metric space. Clearly, therefore, the metric space is not complete since, for example, we found Cauchy sequences of rationals above which converge to  . However, it is a basic result of elementary real analysis that the metric space
. However, it is a basic result of elementary real analysis that the metric space  is complete. It is also a basic result that the completion of a field gives another field, so since is a field it must also be the case that is a field.
is complete. It is also a basic result that the completion of a field gives another field, so since is a field it must also be the case that is a field.
- Archimedian vs. non-archimedian absolute values and ultrametric spaces
In constructing the p-adic number field it becomes important to distinguish between two types of absolute value function on a field, namely archimedian and non-archimedian absolute values. All absolute values on a field by definition have the properties that they assign the value 0 only to the field element 0, they assign the positive value  to each non-zero field element , and they satisfy
to each non-zero field element , and they satisfy  and the usual triangle inequality
and the usual triangle inequality

The usual Euclidean absolute value function used above on , of course, satisfies these conditions, and is called archimedian because it has the property that there is no limit to the size of the absolute values that can be assigned to integers. We can write this as
sup
Non-archimedian absolute values do not have this property. In addition to the basic conditions that all absolute values must satisfy, non-archimedian absolute values must also satisfy the additional condition

which is known as the ultrametric triangle inequality. It is obviously the case that the usual Euclidean absolute value function used above on (an archimedian absolute value function) does not satisfy this ultrametric triangle inequality condition, e.g.,

In fact, it follows from the ultrametric triangle inequality condition that non-archimedian absolute values of integers can never exceed  , because if the condition is to hold for the absolute value function then we can write for any integer :
, because if the condition is to hold for the absolute value function then we can write for any integer :

and so by induction we must have

Then if  we would have
we would have  which implies
which implies  , and so
, and so  in this case. It is not possible for
in this case. It is not possible for  to exceed , so in the case of non-archimedian absolute values we have
to exceed , so in the case of non-archimedian absolute values we have
sup
Any absolute value function which does not satisfy the above ultrametric triangle inequality condition is called archimedian, and these are the only two possible types of absolute values. To see that these are the only two possible types, suppose we have an absolute value function such that
sup
where  . Then there must exist an integer
. Then there must exist an integer  whose absolute value exceeds , and so
whose absolute value exceeds , and so  gets arbitrarily large as
gets arbitrarily large as  grows, so
grows, so 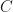 cannot be finite. The absolute value function must be archimedian in this case. Otherwise, we must have
cannot be finite. The absolute value function must be archimedian in this case. Otherwise, we must have  , but since for all absolute values it must be the case that
, but since for all absolute values it must be the case that  , it must be the case that
, it must be the case that  if is finite. Thus we must have a non-archimedian absolute value in this case and there are no other possibilities.
if is finite. Thus we must have a non-archimedian absolute value in this case and there are no other possibilities.
The trick in constructing the p-adic number field from the rationals is to use a certain non-archimedian absolute value function satisfying the ultrametric triangle inequality condition to define the metric over , rather than the usual (archimedian) Euclidean absolute value function. In this regard we have the following:
Theorem 1. Define a metric on a field by . Then the absolute value function in this definition is non-archimedian if and only if for all field elements , 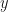 ,
,  we have
we have

Proof: Suppose first that the absolute value function is non-archimedian. Applying it to the equation

gives
Conversely, suppose the given metric inequality holds. Then setting  and
and  in the metric inequality we get
in the metric inequality we get

which is equivalent to

thus proving that the absolute value function is non-archimedian.
A metric for which the inequality in Theorem 1 is true is called an ultrametric, and a space endowed with an ultrametric is called an ultrametric space. Such spaces have curious properties which have been studied extensively. In some ways, however, using a non-archimedian absolute value makes analysis much easier than in the usual archimedian case. In this regard we have the following result pertaining to Cauchy sequences with respect to a non-archimedian absolute value function, which is NOT true for archimedian absolute values:
Theorem 2. A sequence of rational numbers is a Cauchy sequence with respect to a non-archimedian absolute value if and only if we have

Proof: Letting  , we have
, we have



because the absolute value is non-archimedian. We then have that if is Cauchy then the terms get arbitrarily closer as  so we must have . Conversely, if is true, then we must also have
so we must have . Conversely, if is true, then we must also have  for any
for any  , so the conditions of a Cauchy sequence are satisfied.
, so the conditions of a Cauchy sequence are satisfied.
It is important to note that Theorem 2 is false for archimedian absolute values. The classic counterexample involves the partial sums of the harmonic series (which is divergent in terms of Euclidean absolute values). Consider the following three partial sums in particular:



Then we have

so the condition of Theorem 2 is satisfied. However,



Therefore it is not true in this case that for any , so the conditions of a Cauchy sequence are not satisfied here. It is only in the context of non-archimedian absolute values that this works.
- Constructing the p-adic number field as the completion of the rationals
To obtain the p-adic number field as the completion of the field of rationals in a way analogous to how Cantor obtained the reals from the rationals, we use an ultrametric based on a non-archimedian absolute value known as the p-adic absolute value.
For each prime there is an associated p-adic absolute value on obtained by factoring out the powers of in any given rational  to get
to get

with

With this factorisation in hand, the p-adic absolute value of is then defined as

if  , and we set
, and we set  . (As mentioned earlier, the number is called the p-adic valuation of ).
. (As mentioned earlier, the number is called the p-adic valuation of ).
It is straightforward to verify that this is a non-archimedian absolute value on . It has some surprising features. For example, unlike the usual Euclidean absolute value function on which can take any non-negative value on a continuum, the p-adic absolute value function can only take values in the discrete set

For example, in the case of the -adic absolute value we have




Note that the -adic absolute value of is large, while that of  is small.
is small.
Now consider the metric space  where
where  is defined as
is defined as

By virtue of Theorem 1, is an ultrametric and is an ultrametric space. Since the p-adic absolute value function has some counterintuitive features, it is not surprising that also gives some counterintuitive results. For example, the numbers  and
and  are much `closer’ to each other with regard to this ultrametric than the numbers
are much `closer’ to each other with regard to this ultrametric than the numbers  and , because
and , because

whereas

In addition, we can use it to show that the sequence where

is Cauchy with respect to , whereas it is violently non-Cauchy with respect to the usual Euclidean absolute value. We have

It follows from Theorem 2 in the previous section that the sequence is Cauchy with respect to the p-adic absolute value. In fact, the infinite series

has the sum  in the ultrametric space (this formula can be derived in the usual way for geometric series) but its sum is undefined in .
in the ultrametric space (this formula can be derived in the usual way for geometric series) but its sum is undefined in .
The following Theorem proves that the ultrametic space is not complete in a way which is analogous to how is not complete.
Theorem 3. The field of rational numbers is not complete with respect to the p-adic absolute value.
Proof: To prove this, we will create a Cauchy sequence with respect to the p-adic absolute value function whose limit does not belong to .
Let  be an integer. Recall that a property of the Euler totient function is that for any prime and any integer
be an integer. Recall that a property of the Euler totient function is that for any prime and any integer  we have
we have

Also recall the Euler-Fermat Theorem which says that if  then
then
 (mod )
(mod )
With these in hand, consider the sequence  . Then since we have
. Then since we have  , the Euler-Fermat Theorem tells us that
, the Euler-Fermat Theorem tells us that
 (mod
(mod  )
)
Therefore

must be divisible by  , so we have
, so we have

and so the sequence is Cauchy with respect to the p-adic absolute value, by virtue of Theorem 2. If we call the limit of this sequence

we can write the following:






Therefore since  , the limit of the sequence must be a nontrivial
, the limit of the sequence must be a nontrivial  -th root of unity, so it cannot belong to . This proves that the ultrametric space is not complete.
-th root of unity, so it cannot belong to . This proves that the ultrametric space is not complete.
Although is not complete with regard to the p-adic absolute value, we can construct the p-adic completion in a manner analogous to Cantor’s construction of as a completion of . Investigating the fine details of this and the properties of then lead one into the rich literature on p-adic analysis, which I hope to explore further in future notes.














































 denote an integrable random variable with mean
denote an integrable random variable with mean 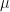 and finite non-zero variance
and finite non-zero variance  , one form of Chebyshev’s inequality says
, one form of Chebyshev’s inequality says
 is a real number.
is a real number. , then we can write Chebyshev’s inequality as
, then we can write Chebyshev’s inequality as

 so that
so that ![\mathbb{E}[g(X)] = \sigma^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28X%29%5D+%3D+%5Csigma%5E2&bg=ffffff&fg=111111&s=0&c=20201002) .
.


 then
then  and
and
 ). However, if
). However, if  then
then  so it is still true that
so it is still true that![\mathbb{E}[\epsilon^2I_A(\omega)] = \epsilon^2P(A) = \epsilon^2P(|X - \mu| \geq \epsilon) \leq \mathbb{E}[g(X(\omega))] = \sigma^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cepsilon%5E2I_A%28%5Comega%29%5D+%3D+%5Cepsilon%5E2P%28A%29+%3D+%5Cepsilon%5E2P%28%7CX+-+%5Cmu%7C+%5Cgeq+%5Cepsilon%29+%5Cleq+%5Cmathbb%7BE%7D%5Bg%28X%28%5Comega%29%29%5D+%3D+%5Csigma%5E2&bg=ffffff&fg=111111&s=0&c=20201002)
 gives Chebyshev’s inequality.
gives Chebyshev’s inequality.  be a sequence of events, i.e., a sequence of subsets of
be a sequence of events, i.e., a sequence of subsets of 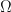 . Then
. Then
 that are in an infinity of the subsets
that are in an infinity of the subsets  . The Borel-Cantelli lemma says the following:
. The Borel-Cantelli lemma says the following: then
then 
 then
then 

 converges, the tail sums
converges, the tail sums  as
as 




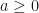 we have
we have  . (To see this, let
. (To see this, let  . Then
. Then  and for
and for  we have
we have  . Therefore
. Therefore 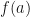 is an increasing function, so
is an increasing function, so  for
for 

 as
as 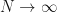 . Therefore
. Therefore  and
and  , so
, so  , so the lemma is proved.
, so the lemma is proved. 
![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=111111&s=0&c=20201002) . Define the mesh of the partition
. Define the mesh of the partition  by
by
 for which
for which  , and in particular for which
, and in particular for which  . For every
. For every  let
let

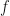 is a real-valued function defined on
is a real-valued function defined on  we will say that
we will say that  variation on
variation on  , if
, if  we will say that
we will say that  , if
, if  we will say that
we will say that 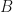 , then we find a curious result:
, then we find a curious result:  almost surely. In other words,
almost surely. In other words, (a.s.)
(a.s.) (a.s.)
(a.s.) (a.s.)
(a.s.)


![\mathbb{E}[Y_n] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BY_n%5D+%3D+0&bg=ffffff&fg=111111&s=0&c=20201002) because
because ![\mathbb{E}[(B(t_i) - B(t_{i-1}))^2] = t_i - t_{i-1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%28B%28t_i%29+-+B%28t_%7Bi-1%7D%29%29%5E2%5D+%3D+t_i+-+t_%7Bi-1%7D&bg=ffffff&fg=111111&s=0&c=20201002) . Therefore
. Therefore![\mathbb{V}[Y_n] = \mathbb{E}[Y_n^2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BV%7D%5BY_n%5D+%3D+%5Cmathbb%7BE%7D%5BY_n%5E2%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= \mathbb{E}\big[\big(\sum_{i=1}^n \big\{(B(t_i) - B(t_{i-1}))^2 - (t_i - t_{i-1})\big\} \big)^2 \big]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D%5Cbig%5B%5Cbig%28%5Csum_%7Bi%3D1%7D%5En+%5Cbig%5C%7B%28B%28t_i%29+-+B%28t_%7Bi-1%7D%29%29%5E2+-+%28t_i+-+t_%7Bi-1%7D%29%5Cbig%5C%7D+%5Cbig%29%5E2+%5Cbig%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= \sum_{i=1}^n \mathbb{E}\big[\big\{(B(t_i) - B(t_{i-1}))^2 - (t_i - t_{i-1})\big\}^2 \big]](https://s0.wp.com/latex.php?latex=%3D+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb%7BE%7D%5Cbig%5B%5Cbig%5C%7B%28B%28t_i%29+-+B%28t_%7Bi-1%7D%29%29%5E2+-+%28t_i+-+t_%7Bi-1%7D%29%5Cbig%5C%7D%5E2+%5Cbig%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= \sum_{i=1}^n \mathbb{E}\big[(B(t_i) - B(t_{i-1}))^4 - 2(t_i - t_{i-1})(B(t_i) - B(t_{i-1}))^2 + (t_i - t_{i-1})^2 \big]](https://s0.wp.com/latex.php?latex=%3D+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb%7BE%7D%5Cbig%5B%28B%28t_i%29+-+B%28t_%7Bi-1%7D%29%29%5E4+-+2%28t_i+-+t_%7Bi-1%7D%29%28B%28t_i%29+-+B%28t_%7Bi-1%7D%29%29%5E2+%2B+%28t_i+-+t_%7Bi-1%7D%29%5E2+%5Cbig%5D&bg=ffffff&fg=111111&s=0&c=20201002)

 and here
and here  )
)


 in
in  ).
).![\sum_{n=1}^{\infty}P(|Y_n| > \epsilon) \leq \sum_{n=1}^{\infty} \frac{\mathbb{E}[Y_n^2]}{\epsilon^2}](https://s0.wp.com/latex.php?latex=%5Csum_%7Bn%3D1%7D%5E%7B%5Cinfty%7DP%28%7CY_n%7C+%3E+%5Cepsilon%29+%5Cleq+%5Csum_%7Bn%3D1%7D%5E%7B%5Cinfty%7D+%5Cfrac%7B%5Cmathbb%7BE%7D%5BY_n%5E2%5D%7D%7B%5Cepsilon%5E2%7D&bg=ffffff&fg=111111&s=0&c=20201002)

 that
that





 to zero. Since the probability of the divergence set is zero, we conclude that
to zero. Since the probability of the divergence set is zero, we conclude that  (a.s.), as required.
(a.s.), as required.  (a.s.)
(a.s.) . Then we can write
. Then we can write

 as
as  (a.s.)
(a.s.) be a sequence of events, i.e., a sequence of subsets of
be a sequence of events, i.e., a sequence of subsets of  the set of elements that are in an infinite number of the subsets
the set of elements that are in an infinite number of the subsets  the set of elements that are in all but a finite number of the subsets
the set of elements that are in all but a finite number of the subsets 

 but the inclusion does not go in the opposite direction because
but the inclusion does not go in the opposite direction because 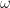 can be in an infinity of sets without being in all but a finite number of them, e.g,
can be in an infinity of sets without being in all but a finite number of them, e.g,  we say the sequence has a limit
we say the sequence has a limit  .
.

 which we denote
which we denote  . The
. The  part means “for some
part means “for some  part means in all
part means in all  .
. is said to converge almost surely to a random variable
is said to converge almost surely to a random variable  iff the probability of the divergence set is zero.
iff the probability of the divergence set is zero. such that
such that
 . Then the divergence set is the set of outcomes for which the above divergence condition is true, which we write as
. Then the divergence set is the set of outcomes for which the above divergence condition is true, which we write as



 is modified to produce a fractional version with stochastic differential equation
is modified to produce a fractional version with stochastic differential equation
 with Hurst parameter
with Hurst parameter  (to be explained below). Similarly, one finds numerous attempts to modify the famous Black-Scholes framework of mathematical finance to incorporate fractional Brownian motion with a view to capturing more long-term memory effects on market movements.
(to be explained below). Similarly, one finds numerous attempts to modify the famous Black-Scholes framework of mathematical finance to incorporate fractional Brownian motion with a view to capturing more long-term memory effects on market movements. , as will be shown below. Both are self-similar processes (i.e., fractals, or `scale invariant’, or ‘self-affine’ – numerous equivalent terms are used in the literature). In this note I want to clarify for myself some basic aspects of standard Brownian motion and fractional Brownian motion as self-similar stochastic processes.
, as will be shown below. Both are self-similar processes (i.e., fractals, or `scale invariant’, or ‘self-affine’ – numerous equivalent terms are used in the literature). In this note I want to clarify for myself some basic aspects of standard Brownian motion and fractional Brownian motion as self-similar stochastic processes.

 is self-similar if there exists a unique
is self-similar if there exists a unique  (called a Hurst parameter) such that for any
(called a Hurst parameter) such that for any 
 , a.s.)
, a.s.) are independent of
are independent of  .
. be H-sssi, and suppose
be H-sssi, and suppose ![\mathbb{E}[X^2(1)] < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5E2%281%29%5D+%3C+%5Cinfty&bg=ffffff&fg=111111&s=0&c=20201002) . Then
. Then![\mathbb{E}[X(t)X(s)] = \frac{1}{2}\{t^{2H} + s^{2H} - |t - s|^{2H}\}\mathbb{E}[X^2(1)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%28t%29X%28s%29%5D+%3D+%5Cfrac%7B1%7D%7B2%7D%5C%7Bt%5E%7B2H%7D+%2B+s%5E%7B2H%7D+-+%7Ct+-+s%7C%5E%7B2H%7D%5C%7D%5Cmathbb%7BE%7D%5BX%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![\mathbb{E}[X^2(t)] = \mathbb{E}[X(t)X(t)] = \mathbb{E}[t^H X(1)t^H X(1)] = t^{2H}\mathbb{E}[X^2(1)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5E2%28t%29%5D+%3D+%5Cmathbb%7BE%7D%5BX%28t%29X%28t%29%5D+%3D+%5Cmathbb%7BE%7D%5Bt%5EH+X%281%29t%5EH+X%281%29%5D+%3D+t%5E%7B2H%7D%5Cmathbb%7BE%7D%5BX%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![\mathbb{E}[(X(t) - X(s))^2] = \mathbb{E}[X^2(|t - s|)] = |t - s|^{2H}\mathbb{E}[X^2(1)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%28X%28t%29+-+X%28s%29%29%5E2%5D+%3D+%5Cmathbb%7BE%7D%5BX%5E2%28%7Ct+-+s%7C%29%5D+%3D+%7Ct+-+s%7C%5E%7B2H%7D%5Cmathbb%7BE%7D%5BX%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![\mathbb{E}[X(t)X(s)] \equiv \frac{1}{2}\{\mathbb{E}[(X^2(t)] + \mathbb{E}[(X^2(s)] - \mathbb{E}[(X(t) - X(s))^2]\}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%28t%29X%28s%29%5D+%5Cequiv+%5Cfrac%7B1%7D%7B2%7D%5C%7B%5Cmathbb%7BE%7D%5B%28X%5E2%28t%29%5D+%2B+%5Cmathbb%7BE%7D%5B%28X%5E2%28s%29%5D+-+%5Cmathbb%7BE%7D%5B%28X%28t%29+-+X%28s%29%29%5E2%5D%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![= \frac{1}{2}\{t^{2H} + s^{2H} - |t - s|^{2H}\}\mathbb{E}[X^2(1)]](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7B1%7D%7B2%7D%5C%7Bt%5E%7B2H%7D+%2B+s%5E%7B2H%7D+-+%7Ct+-+s%7C%5E%7B2H%7D%5C%7D%5Cmathbb%7BE%7D%5BX%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
 and for any partition
and for any partition  ,
,  , . . .,
, . . .,  are independent.
are independent. is a standard Brownian motion if it satisfies the following four conditions:
is a standard Brownian motion if it satisfies the following four conditions: , a.s.
, a.s. ,
, 
 is
is  -sssi.
-sssi.

 . With regard to (iii), the normality and mean zero of
. With regard to (iii), the normality and mean zero of ![\mathbb{E}[(a^{-\frac{1}{2}}B(at))^2] = a^{-1} \cdot at = t](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%28a%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7DB%28at%29%29%5E2%5D+%3D+a%5E%7B-1%7D+%5Ccdot+at+%3D+t&bg=ffffff&fg=111111&s=0&c=20201002)
![\mathbb{E}[B(t)B(s)] = \text{min}\{t, s\}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BB%28t%29B%28s%29%5D+%3D+%5Ctext%7Bmin%7D%5C%7Bt%2C+s%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002) .
.![\mathbb{E}[B(t)B(s)] = \frac{1}{2}\{t + s - |t - s|\} \equiv \text{min}\{t, s\}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BB%28t%29B%28s%29%5D+%3D+%5Cfrac%7B1%7D%7B2%7D%5C%7Bt+%2B+s+-+%7Ct+-+s%7C%5C%7D+%5Cequiv+%5Ctext%7Bmin%7D%5C%7Bt%2C+s%5C%7D&bg=ffffff&fg=111111&s=0&c=20201002) .
. be a probability space on which is defined a stochastic process
be a probability space on which is defined a stochastic process  . A filtration for the stochastic process is a collection of
. A filtration for the stochastic process is a collection of  -algebras
-algebras  satisfying:
satisfying: for
for 
 , the stochastic process
, the stochastic process  at time
at time  is
is  -measurable.
-measurable. is then called the filtered probability space for the process.
is then called the filtered probability space for the process. . Condition (ii) says that the information available at time
. Condition (ii) says that the information available at time  we have
we have![\mathbb{E}[X(t + s) | \mathscr{F}(t)] = X(t)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%28t+%2B+s%29+%7C+%5Cmathscr%7BF%7D%28t%29%5D+%3D+X%28t%29&bg=ffffff&fg=111111&s=0&c=20201002) , a.s.
, a.s. , while failing to be a martingale with respect to a different measure
, while failing to be a martingale with respect to a different measure  is a martingale.
is a martingale.![\mathbb{E}[B(t)] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BB%28t%29%5D+%3D+0&bg=ffffff&fg=111111&s=0&c=20201002) for all
for all  we have
we have![\mathbb{E}[B(t) | \mathscr{F}(s)] \equiv \mathbb{E}[B(s) | \mathscr{F}(s)] + \mathbb{E}[B(t) - B(s) | \mathscr{F}(s)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BB%28t%29+%7C+%5Cmathscr%7BF%7D%28s%29%5D+%5Cequiv+%5Cmathbb%7BE%7D%5BB%28s%29+%7C+%5Cmathscr%7BF%7D%28s%29%5D+%2B+%5Cmathbb%7BE%7D%5BB%28t%29+-+B%28s%29+%7C+%5Cmathscr%7BF%7D%28s%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= B(s) + \mathbb{E}[B(t) - B(s)]](https://s0.wp.com/latex.php?latex=%3D+B%28s%29+%2B+%5Cmathbb%7BE%7D%5BB%28t%29+-+B%28s%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)

 is known for certain when
is known for certain when 

 gives
gives
 ,
,  , and higher. However, `zooming in’ on the path of a Brownian motion does not lead to a straight line, and in the context of this Taylor expansion that translates into the fact that we can no longer discard the
, and higher. However, `zooming in’ on the path of a Brownian motion does not lead to a straight line, and in the context of this Taylor expansion that translates into the fact that we can no longer discard the ![[0, t]](https://s0.wp.com/latex.php?latex=%5B0%2C+t%5D&bg=ffffff&fg=111111&s=0&c=20201002) into a partition
into a partition
 . Then we have
. Then we have
![= \lim\limits_{n \rightarrow \infty} t \sum_{i=1}^n \frac{1}{n}\bigg(\frac{B\big(\frac{t}{n}\big)}{\sqrt{\frac{t}{n}}}\bigg)^2 = t \mathbb{E}[Z^2] = t \mathbb{V}[Z] = t](https://s0.wp.com/latex.php?latex=%3D+%5Clim%5Climits_%7Bn+%5Crightarrow+%5Cinfty%7D+t+%5Csum_%7Bi%3D1%7D%5En+%5Cfrac%7B1%7D%7Bn%7D%5Cbigg%28%5Cfrac%7BB%5Cbig%28%5Cfrac%7Bt%7D%7Bn%7D%5Cbig%29%7D%7B%5Csqrt%7B%5Cfrac%7Bt%7D%7Bn%7D%7D%7D%5Cbigg%29%5E2+%3D+t+%5Cmathbb%7BE%7D%5BZ%5E2%5D+%3D+t+%5Cmathbb%7BV%7D%5BZ%5D+%3D+t&bg=ffffff&fg=111111&s=0&c=20201002)

 is
is  , which shows that in the case of Brownian motion the
, which shows that in the case of Brownian motion the  , not zero. However, the higher order terms can be discarded because for integers
, not zero. However, the higher order terms can be discarded because for integers  we get
we get
![= t^{m/2} \bigg(\lim\limits_{n \rightarrow \infty} \frac{1}{n^{(m-2)/2}}\bigg) \cdot(\mathbb{E}[Z^m]) = 0](https://s0.wp.com/latex.php?latex=%3D+t%5E%7Bm%2F2%7D+%5Cbigg%28%5Clim%5Climits_%7Bn+%5Crightarrow+%5Cinfty%7D+%5Cfrac%7B1%7D%7Bn%5E%7B%28m-2%29%2F2%7D%7D%5Cbigg%29+%5Ccdot%28%5Cmathbb%7BE%7D%5BZ%5Em%5D%29+%3D+0&bg=ffffff&fg=111111&s=0&c=20201002)
 for integers
for integers  from the fact that
from the fact that  , since
, since  ). Using these results in the above Taylor series expansion we get the differential form of Itô’s formula.
). Using these results in the above Taylor series expansion we get the differential form of Itô’s formula. 
 obeys. Taking the function
obeys. Taking the function  we get
we get





 . A mean-zero Gaussian process
. A mean-zero Gaussian process  is called a fractional Brownian motion with Hurst parameter
is called a fractional Brownian motion with Hurst parameter 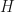 if
if![\mathbb{E}[B_H(t)B_H(s)] = \frac{1}{2}\{t^{2H} + s^{2H} - |t - s|^{2H}\}\mathbb{E}[B_H^2(1)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BB_H%28t%29B_H%28s%29%5D+%3D+%5Cfrac%7B1%7D%7B2%7D%5C%7Bt%5E%7B2H%7D+%2B+s%5E%7B2H%7D+-+%7Ct+-+s%7C%5E%7B2H%7D%5C%7D%5Cmathbb%7BE%7D%5BB_H%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
 does not have independent increments.
does not have independent increments.![\mathbb{E}[(B_H(t) - B_H(s))^2] = \mathbb{E}[B_H^2(t)] + \mathbb{E}[B_H^2(s)] - 2\mathbb{E}[B_H(t)B_H(s)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%28B_H%28t%29+-+B_H%28s%29%29%5E2%5D+%3D+%5Cmathbb%7BE%7D%5BB_H%5E2%28t%29%5D+%2B+%5Cmathbb%7BE%7D%5BB_H%5E2%28s%29%5D+-+2%5Cmathbb%7BE%7D%5BB_H%28t%29B_H%28s%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= |t - s|^{2H}\mathbb{E}[B_H^2(1)]](https://s0.wp.com/latex.php?latex=%3D+%7Ct+-+s%7C%5E%7B2H%7D%5Cmathbb%7BE%7D%5BB_H%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
 , the two processes
, the two processes  and
and  have the same distribution. To prove that fractional Brownian motion with
have the same distribution. To prove that fractional Brownian motion with 
 . The increments
. The increments  have zero mean, variance
have zero mean, variance![\mathbb{E}[b_H^2(j)] = \mathbb{E}[(B_H(j+1) - B_H(j))^2] = \mathbb{E}[B_H^2(1)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bb_H%5E2%28j%29%5D+%3D+%5Cmathbb%7BE%7D%5B%28B_H%28j%2B1%29+-+B_H%28j%29%29%5E2%5D+%3D+%5Cmathbb%7BE%7D%5BB_H%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![\mathbb{E}[b_H(j) b_H(k)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bb_H%28j%29+b_H%28k%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= \mathbb{E}[B_H(j+1)B_H(k+1) - B_H(j+1)B_H(k) - B_H(k+1)B_H(j) + B_H(j)B_H(k)]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D%5BB_H%28j%2B1%29B_H%28k%2B1%29+-+B_H%28j%2B1%29B_H%28k%29+-+B_H%28k%2B1%29B_H%28j%29+%2B+B_H%28j%29B_H%28k%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)



![+ |j|^{2H} + |k|^{2H} - |j - k|^{2H}\bigg\}\mathbb{E}[B_H^2(1)]](https://s0.wp.com/latex.php?latex=%2B+%7Cj%7C%5E%7B2H%7D+%2B+%7Ck%7C%5E%7B2H%7D+-+%7Cj+-+k%7C%5E%7B2H%7D%5Cbigg%5C%7D%5Cmathbb%7BE%7D%5BB_H%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= \bigg\{|j - k + 1|^{2H} - 2|j - k|^{2H} + |j - k - 1|^{2H}\bigg\}\mathbb{E}[B_H^2(1)]](https://s0.wp.com/latex.php?latex=%3D+%5Cbigg%5C%7B%7Cj+-+k+%2B+1%7C%5E%7B2H%7D+-+2%7Cj+-+k%7C%5E%7B2H%7D+%2B+%7Cj+-+k+-+1%7C%5E%7B2H%7D%5Cbigg%5C%7D%5Cmathbb%7BE%7D%5BB_H%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
 . Then the expression reduces to
. Then the expression reduces to![\mathbb{E}[b_H(j) b_H(k)] = \bigg\{(j - k + 1)^{2H} - 2(j - k)^{2H} + (j - k - 1)^{2H}\bigg\}\mathbb{E}[B_H^2(1)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bb_H%28j%29+b_H%28k%29%5D+%3D+%5Cbigg%5C%7B%28j+-+k+%2B+1%29%5E%7B2H%7D+-+2%28j+-+k%29%5E%7B2H%7D+%2B+%28j+-+k+-+1%29%5E%7B2H%7D%5Cbigg%5C%7D%5Cmathbb%7BE%7D%5BB_H%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)


 is a constant.
is a constant.
 is H-ss. To see this, make the change of variable
is H-ss. To see this, make the change of variable  . We get
. We get



 by Result 2, or we can say
by Result 2, or we can say  ). The process
). The process ![\mathbb{E}[(Z(t) - Z(s))^2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%28Z%28t%29+-+Z%28s%29%29%5E2%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= \mathbb{E}\bigg[c_H\int_{\mathbb{R}} [I_{\{u \leq t\}}(t - u)^{H - \frac{1}{2}} - I_{\{u \leq s\}}(s - u)^{H - \frac{1}{2}}]^2du \bigg]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D%5Cbigg%5Bc_H%5Cint_%7B%5Cmathbb%7BR%7D%7D+%5BI_%7B%5C%7Bu+%5Cleq+t%5C%7D%7D%28t+-+u%29%5E%7BH+-+%5Cfrac%7B1%7D%7B2%7D%7D+-+I_%7B%5C%7Bu+%5Cleq+s%5C%7D%7D%28s+-+u%29%5E%7BH+-+%5Cfrac%7B1%7D%7B2%7D%7D%5D%5E2du+%5Cbigg%5D&bg=ffffff&fg=111111&s=0&c=20201002)
 this becomes
this becomes![= \mathbb{E}\bigg[c_H\int_{\mathbb{R}} [I_{\{m \leq t - s\}}((t - s) - m)^{H - \frac{1}{2}} - I_{\{m \leq 0\}}(-m)^{H - \frac{1}{2}}]^2du \bigg]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D%5Cbigg%5Bc_H%5Cint_%7B%5Cmathbb%7BR%7D%7D+%5BI_%7B%5C%7Bm+%5Cleq+t+-+s%5C%7D%7D%28%28t+-+s%29+-+m%29%5E%7BH+-+%5Cfrac%7B1%7D%7B2%7D%7D+-+I_%7B%5C%7Bm+%5Cleq+0%5C%7D%7D%28-m%29%5E%7BH+-+%5Cfrac%7B1%7D%7B2%7D%7D%5D%5E2du+%5Cbigg%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![= |t - s|^{2H}\mathbb{E}[Z^2(1)]](https://s0.wp.com/latex.php?latex=%3D+%7Ct+-+s%7C%5E%7B2H%7D%5Cmathbb%7BE%7D%5BZ%5E2%281%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)

 is the gravitational force,
is the gravitational force,  is the Newtonian gravitational constant and
is the Newtonian gravitational constant and  is the (differential) mass density. The link with the scalar potential through
is the (differential) mass density. The link with the scalar potential through  gives us
gives us

 is an unspecified function,
is an unspecified function,  is a mass which can be taken as being located at the origin,
is a mass which can be taken as being located at the origin,  is the radial distance from the origin, and
is the radial distance from the origin, and  is a radial unit vector.
is a radial unit vector. of radius
of radius 



 comes from).
comes from). we must have
we must have  where
where  is some unspecified function of
is some unspecified function of 

 we get
we get
 we see that this is nearly Gauss’s law:
we see that this is nearly Gauss’s law:
 at this final stage.
at this final stage. -sphere by a homeomorphism linking these two spaces. When I did the calculations, I was amazed to find that prime numbers are mapped to a family of Pythagorean triples on the
-sphere by a homeomorphism linking these two spaces. When I did the calculations, I was amazed to find that prime numbers are mapped to a family of Pythagorean triples on the 
 ,
,  and
and  in the diagram. Since they are collinear, there must be a scalar
in the diagram. Since they are collinear, there must be a scalar  such that
such that








 is the homeomorphism which maps points on the
is the homeomorphism which maps points on the  which maps points on the extended real line to the
which maps points on the extended real line to the 
 we have
we have  so the above equation can be written as
so the above equation can be written as





 is a prime, the corresponding point on the
is a prime, the corresponding point on the 
 ,
,  and
and  are then Pythagorean triples, as can easily be demonstrated by showing that these terms satisfy the identity
are then Pythagorean triples, as can easily be demonstrated by showing that these terms satisfy the identity
 , i.e., an explicit homeomorphism which establishes the topological equivalence of the
, i.e., an explicit homeomorphism which establishes the topological equivalence of the  -sphere and the extended complex plane, giving rise to the name Riemann sphere for the latter.
-sphere and the extended complex plane, giving rise to the name Riemann sphere for the latter. , namely
, namely
 is identified with the plane
is identified with the plane  by identifying
by identifying  ,
,  , with
, with  for all
for all  . The point
. The point  is identified as the `north pole’ of
is identified as the `north pole’ of  , and stereographic projections from
, and stereographic projections from  and
and 


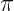 is in fact a homeomorphism (i.e., a continuous bijection from
is in fact a homeomorphism (i.e., a continuous bijection from  to
to  where
where  , and let
, and let






 , we observe that
, we observe that


 )
)







 are continuous, so
are continuous, so 
 , known as the point at infinity, is the distinguishing feature that makes the geometry of the present context non-Euclidean (it can be viewed as the point in this geometry where lines which start out parallel eventually meet, something which is impossible in Euclidean geometry). With the addition of the point at infinity into the picture we get the full homeomorphism
, known as the point at infinity, is the distinguishing feature that makes the geometry of the present context non-Euclidean (it can be viewed as the point in this geometry where lines which start out parallel eventually meet, something which is impossible in Euclidean geometry). With the addition of the point at infinity into the picture we get the full homeomorphism
 is referred to as the Riemann sphere. It is because the extended complex plane is homeomorphic (i.e., topologically equivalent) to the
is referred to as the Riemann sphere. It is because the extended complex plane is homeomorphic (i.e., topologically equivalent) to the  with large magnitude
with large magnitude  , i.e., to complex numbers which are `closer to infinity’ in a sense. Similarly, points
, i.e., to complex numbers which are `closer to infinity’ in a sense. Similarly, points  on the
on the  correspond to complex numbers
correspond to complex numbers  with small magnitude
with small magnitude  . Points on the equator of the
. Points on the equator of the  in the complex plane. The situation is illustrated in the following diagram:
in the complex plane. The situation is illustrated in the following diagram: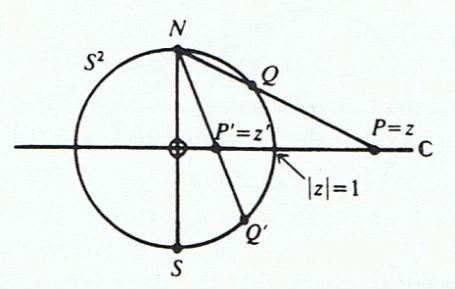
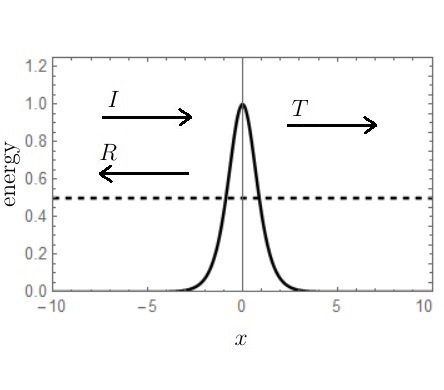

 is the height of the potential at the origin and
is the height of the potential at the origin and  is its width. We assume that a travelling wave of predetermined amplitude
is its width. We assume that a travelling wave of predetermined amplitude  is moving from left to right towards the origin, corresponding to a free particle of mass
is moving from left to right towards the origin, corresponding to a free particle of mass  and energy
and energy  , where
, where  . The particle is scattered in the region around the origin where the potential is nonzero, being reflected with probability
. The particle is scattered in the region around the origin where the potential is nonzero, being reflected with probability  and transmitted (by quantum tunnelling, since
and transmitted (by quantum tunnelling, since  ) with probability
) with probability  . Usually, the main focus in scattering problems is on the calculation of
. Usually, the main focus in scattering problems is on the calculation of ![-\frac{\hbar^2}{2m} \frac{d^2\psi}{dx^2} + \bigg[\frac{V_0}{\cosh^2\big(\frac{x}{a}\big)} - E\bigg]\psi = 0](https://s0.wp.com/latex.php?latex=-%5Cfrac%7B%5Chbar%5E2%7D%7B2m%7D+%5Cfrac%7Bd%5E2%5Cpsi%7D%7Bdx%5E2%7D+%2B+%5Cbigg%5B%5Cfrac%7BV_0%7D%7B%5Ccosh%5E2%5Cbig%28%5Cfrac%7Bx%7D%7Ba%7D%5Cbig%29%7D+-+E%5Cbigg%5D%5Cpsi+%3D+0&bg=ffffff&fg=111111&s=2&c=20201002)
 to get
to get![\frac{1}{2} \frac{d^2\psi}{dx^2} + [E^{\prime} - V^{\prime}]\psi = 0](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D+%5Cfrac%7Bd%5E2%5Cpsi%7D%7Bdx%5E2%7D+%2B+%5BE%5E%7B%5Cprime%7D+-+V%5E%7B%5Cprime%7D%5D%5Cpsi+%3D+0&bg=ffffff&fg=111111&s=2&c=20201002)


 explicitly, we observe that far away from the origin the potential is zero, so the above equation reduces to
explicitly, we observe that far away from the origin the potential is zero, so the above equation reduces to

 is the wavenumber. We are free to assign any positive value we like to the wavenumber
is the wavenumber. We are free to assign any positive value we like to the wavenumber  here, which implies
here, which implies  .
. explicitly, we note that we are able to assign any value we like to
explicitly, we note that we are able to assign any value we like to  and
and  to give us the rescaled potential
to give us the rescaled potential
![\frac{1}{2} \frac{d^2\psi}{dx^2} + \bigg[\frac{1}{2} - \frac{1}{\cosh^2(x)}\bigg]\psi = 0](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D+%5Cfrac%7Bd%5E2%5Cpsi%7D%7Bdx%5E2%7D+%2B+%5Cbigg%5B%5Cfrac%7B1%7D%7B2%7D+-+%5Cfrac%7B1%7D%7B%5Ccosh%5E2%28x%29%7D%5Cbigg%5D%5Cpsi+%3D+0&bg=ffffff&fg=111111&s=2&c=20201002)
![{}_2F_1\big([\alpha, \beta], [\gamma], z\big)](https://s0.wp.com/latex.php?latex=%7B%7D_2F_1%5Cbig%28%5B%5Calpha%2C+%5Cbeta%5D%2C+%5B%5Cgamma%5D%2C+z%5Cbig%29&bg=ffffff&fg=111111&s=2&c=20201002) , i.e., with two upper parameters,
, i.e., with two upper parameters,  and
and  , and one lower parameter,
, and one lower parameter,  . (For details, see ter Haar, D, 1975, Problems in quantum mechanics, London: Pion, Chapter 1, Problem 14, Chapter 2, Problem 8, and also Blinder, S, 2011, Scattering by a Symmetrical Eckart Potential, Wolfram Demonstrations Project). Here we will focus on adapting the (rather complicated) exact solution to the case specified above. Given the four parameters
. (For details, see ter Haar, D, 1975, Problems in quantum mechanics, London: Pion, Chapter 1, Problem 14, Chapter 2, Problem 8, and also Blinder, S, 2011, Scattering by a Symmetrical Eckart Potential, Wolfram Demonstrations Project). Here we will focus on adapting the (rather complicated) exact solution to the case specified above. Given the four parameters  , let
, let![\lambda = \frac{1}{4}\bigg[\sqrt{1 - \frac{8mV_0a^2}{\hbar^2}} - 1\bigg]](https://s0.wp.com/latex.php?latex=%5Clambda+%3D+%5Cfrac%7B1%7D%7B4%7D%5Cbigg%5B%5Csqrt%7B1+-+%5Cfrac%7B8mV_0a%5E2%7D%7B%5Chbar%5E2%7D%7D+-+1%5Cbigg%5D&bg=ffffff&fg=111111&s=2&c=20201002)


![\psi = \bigg[\cosh^2\bigg(\frac{x}{a}\bigg)\bigg]^{-2\lambda}\cdot{}_2F_1\bigg(\bigg[-\lambda+\frac{ika}{2}, -\lambda - \frac{ika}{2}\bigg], \bigg[\frac{1}{2}\bigg], -\sinh^2\bigg(\frac{x}{a}\bigg)\bigg)](https://s0.wp.com/latex.php?latex=%5Cpsi+%3D+%5Cbigg%5B%5Ccosh%5E2%5Cbigg%28%5Cfrac%7Bx%7D%7Ba%7D%5Cbigg%29%5Cbigg%5D%5E%7B-2%5Clambda%7D%5Ccdot%7B%7D_2F_1%5Cbigg%28%5Cbigg%5B-%5Clambda%2B%5Cfrac%7Bika%7D%7B2%7D%2C+-%5Clambda+-+%5Cfrac%7Bika%7D%7B2%7D%5Cbigg%5D%2C+%5Cbigg%5B%5Cfrac%7B1%7D%7B2%7D%5Cbigg%5D%2C+-%5Csinh%5E2%5Cbigg%28%5Cfrac%7Bx%7D%7Ba%7D%5Cbigg%29%5Cbigg%29&bg=ffffff&fg=111111&s=0&c=20201002)
![-\frac{a_1}{a_2} \bigg[\cosh\bigg(\frac{x}{a}\bigg)\bigg]^{-2\lambda} \cdot \sinh\bigg(\frac{x}{a}\bigg)\cdot{}_2F_1\bigg(\bigg[-\lambda+\frac{ika}{2}+\frac{1}{2}, -\lambda - \frac{ika}{2}+\frac{1}{2}\bigg], \bigg[\frac{3}{2}\bigg], -\sinh^2\bigg(\frac{x}{a}\bigg)\bigg)](https://s0.wp.com/latex.php?latex=-%5Cfrac%7Ba_1%7D%7Ba_2%7D+%5Cbigg%5B%5Ccosh%5Cbigg%28%5Cfrac%7Bx%7D%7Ba%7D%5Cbigg%29%5Cbigg%5D%5E%7B-2%5Clambda%7D+%5Ccdot+%5Csinh%5Cbigg%28%5Cfrac%7Bx%7D%7Ba%7D%5Cbigg%29%5Ccdot%7B%7D_2F_1%5Cbigg%28%5Cbigg%5B-%5Clambda%2B%5Cfrac%7Bika%7D%7B2%7D%2B%5Cfrac%7B1%7D%7B2%7D%2C+-%5Clambda+-+%5Cfrac%7Bika%7D%7B2%7D%2B%5Cfrac%7B1%7D%7B2%7D%5Cbigg%5D%2C+%5Cbigg%5B%5Cfrac%7B3%7D%7B2%7D%5Cbigg%5D%2C+-%5Csinh%5E2%5Cbigg%28%5Cfrac%7Bx%7D%7Ba%7D%5Cbigg%29%5Cbigg%29&bg=ffffff&fg=111111&s=0&c=20201002)
 ,
,  and
and 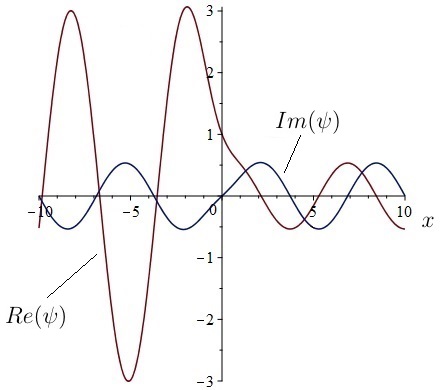


 we get a probability of reflection
we get a probability of reflection  and a probability of transmission
and a probability of transmission  .
.



 by solving the second-order homogeneous linear differential equation
by solving the second-order homogeneous linear differential equation

 … the boundary conditions can be fulfilled if and only if
… the boundary conditions can be fulfilled if and only if  is the square of an integer
is the square of an integer  .
. ,
,  and
and  . Suppose first that
. Suppose first that  and the auxiliary equation for (13) is
and the auxiliary equation for (13) is


 and
and  are constants to be determined from the boundary conditions. From the boundary condition
are constants to be determined from the boundary conditions. From the boundary condition  we conclude that
we conclude that  so the equation reduces to
so the equation reduces to
 we are forced to conclude that
we are forced to conclude that  since
since  . Therefore there is only the trivial solution
. Therefore there is only the trivial solution  in the case
in the case 

 and the auxiliary equation is
and the auxiliary equation is


 , then we must have
, then we must have  where
where  . Thus, we find that for each
. Thus, we find that for each  , and the corresponding eigenfunctions are
, and the corresponding eigenfunctions are  . The coefficient
. The coefficient  between
between  and
and  .
. ) but not a maximum one, and for each eigenvalue there is a unique eigenfunction (up to a multiplicative constant). Also, importantly, the eigenfunctions here form a complete and orthogonal set of functions. Orthogonality refers to the fact that the integral of a product of any two distinct eigenfunctions over the interval
) but not a maximum one, and for each eigenvalue there is a unique eigenfunction (up to a multiplicative constant). Also, importantly, the eigenfunctions here form a complete and orthogonal set of functions. Orthogonality refers to the fact that the integral of a product of any two distinct eigenfunctions over the interval  is zero, i.e.,
is zero, i.e.,
 , as can easily be demonstrated in the same way as in the theory of Fourier series. Completeness refers to the fact that over the interval
, as can easily be demonstrated in the same way as in the theory of Fourier series. Completeness refers to the fact that over the interval  ,
,  using a Fourier series of the form
using a Fourier series of the form


 .
.

 and multiplying through by
and multiplying through by  we get
we get




 , so results concerning the properties of
, so results concerning the properties of 
 is a real-valued positive weight function and
is a real-valued positive weight function and  . This differential equation is often written out in full as
. This differential equation is often written out in full as
![x \in [a, b]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5Ba%2C+b%5D&bg=ffffff&fg=111111&s=2&c=20201002) . In Sturm-Liouville problems, the functions
. In Sturm-Liouville problems, the functions  and
and  . The boundary conditions are a key aspect of each Sturm-Liouville problem; for a given form of the differential equation, different boundary conditions can produce very different problems. Solving a Sturm-Liouville problem involves finding the values of
. The boundary conditions are a key aspect of each Sturm-Liouville problem; for a given form of the differential equation, different boundary conditions can produce very different problems. Solving a Sturm-Liouville problem involves finding the values of  ,
,  and
and  in the defining Sturm-Liouville differential equation.
in the defining Sturm-Liouville differential equation. to denote the complex conjugate of the function
to denote the complex conjugate of the function  and
and  over the interval
over the interval 

 and
and ![v(Lu)^{*} - u^{*} Lv = \frac{\mathrm{d}}{\mathrm{d} x} \bigg[p(x) \bigg(v \frac{\mathrm{d}u^{*}}{\mathrm{d}x} - u^{*}\frac{\mathrm{d}v}{\mathrm{d}x}\bigg) \bigg]](https://s0.wp.com/latex.php?latex=v%28Lu%29%5E%7B%2A%7D+-+u%5E%7B%2A%7D+Lv+%3D+%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%5Bp%28x%29+%5Cbigg%28v+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7Dx%7D+-+u%5E%7B%2A%7D%5Cfrac%7B%5Cmathrm%7Bd%7Dv%7D%7B%5Cmathrm%7Bd%7Dx%7D%5Cbigg%29+%5Cbigg%5D&bg=ffffff&fg=111111&s=2&c=20201002)

![= v\bigg[\frac{\mathrm{d}}{\mathrm{d} x} \bigg(p(x) \frac{\mathrm{d}u^{*}}{\mathrm{d} x} \bigg) + q(x) u^{*}\bigg] - u^{*} \bigg[\frac{\mathrm{d}}{\mathrm{d} x} \bigg(p(x) \frac{\mathrm{d} v}{\mathrm{d} x} \bigg) + q(x) v\bigg]](https://s0.wp.com/latex.php?latex=%3D+v%5Cbigg%5B%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%28p%28x%29+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%29+%2B+q%28x%29+u%5E%7B%2A%7D%5Cbigg%5D+-+u%5E%7B%2A%7D+%5Cbigg%5B%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%28p%28x%29+%5Cfrac%7B%5Cmathrm%7Bd%7D+v%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%29+%2B+q%28x%29+v%5Cbigg%5D&bg=ffffff&fg=111111&s=2&c=20201002)



![= \frac{\mathrm{d}}{\mathrm{d} x} \bigg[p(x) \bigg(v \frac{\mathrm{d}u^{*}}{\mathrm{d}x} - u^{*}\frac{\mathrm{d}v}{\mathrm{d}x}\bigg) \bigg]](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%5Bp%28x%29+%5Cbigg%28v+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7Dx%7D+-+u%5E%7B%2A%7D%5Cfrac%7B%5Cmathrm%7Bd%7Dv%7D%7B%5Cmathrm%7Bd%7Dx%7D%5Cbigg%29+%5Cbigg%5D&bg=ffffff&fg=111111&s=2&c=20201002)

![= \int_a^b \frac{\mathrm{d}}{\mathrm{d} x} \bigg[p(x) \bigg(v \frac{\mathrm{d}u^{*}}{\mathrm{d}x} - u^{*}\frac{\mathrm{d}v}{\mathrm{d}x}\bigg) \bigg] \mathrm{d} x](https://s0.wp.com/latex.php?latex=%3D+%5Cint_a%5Eb+%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%5Bp%28x%29+%5Cbigg%28v+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7Dx%7D+-+u%5E%7B%2A%7D%5Cfrac%7B%5Cmathrm%7Bd%7Dv%7D%7B%5Cmathrm%7Bd%7Dx%7D%5Cbigg%29+%5Cbigg%5D+%5Cmathrm%7Bd%7D+x&bg=ffffff&fg=111111&s=2&c=20201002)
![= \int_a^b \mathrm{d} \bigg[p(x) \bigg(v \frac{\mathrm{d}u^{*}}{\mathrm{d}x} - u^{*}\frac{\mathrm{d}v}{\mathrm{d}x}\bigg) \bigg]](https://s0.wp.com/latex.php?latex=%3D+%5Cint_a%5Eb+%5Cmathrm%7Bd%7D+%5Cbigg%5Bp%28x%29+%5Cbigg%28v+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7Dx%7D+-+u%5E%7B%2A%7D%5Cfrac%7B%5Cmathrm%7Bd%7Dv%7D%7B%5Cmathrm%7Bd%7Dx%7D%5Cbigg%29+%5Cbigg%5D&bg=ffffff&fg=111111&s=2&c=20201002)
![= \bigg[p(x) \bigg(v \frac{\mathrm{d}u^{*}}{\mathrm{d}x} - u^{*}\frac{\mathrm{d}v}{\mathrm{d}x}\bigg) \bigg]_a^b](https://s0.wp.com/latex.php?latex=%3D+%5Cbigg%5Bp%28x%29+%5Cbigg%28v+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7Dx%7D+-+u%5E%7B%2A%7D%5Cfrac%7B%5Cmathrm%7Bd%7Dv%7D%7B%5Cmathrm%7Bd%7Dx%7D%5Cbigg%29+%5Cbigg%5D_a%5Eb&bg=ffffff&fg=111111&s=2&c=20201002)



 and
and  satisfy these boundary conditions. Then at
satisfy these boundary conditions. Then at 




![\bigg[p(x) \bigg(v \frac{\mathrm{d}u^{*}}{\mathrm{d}x} - u^{*}\frac{\mathrm{d}v}{\mathrm{d}x}\bigg) \bigg]_a^b = 0](https://s0.wp.com/latex.php?latex=%5Cbigg%5Bp%28x%29+%5Cbigg%28v+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7Dx%7D+-+u%5E%7B%2A%7D%5Cfrac%7B%5Cmathrm%7Bd%7Dv%7D%7B%5Cmathrm%7Bd%7Dx%7D%5Cbigg%29+%5Cbigg%5D_a%5Eb+%3D+0&bg=ffffff&fg=111111&s=2&c=20201002)
 . If
. If 


![\bigg[p(x) \bigg(v \frac{\mathrm{d}u^{*}}{\mathrm{d}x} - u^{*}\frac{\mathrm{d}v}{\mathrm{d}x}\bigg) \bigg]_a^b](https://s0.wp.com/latex.php?latex=%5Cbigg%5Bp%28x%29+%5Cbigg%28v+%5Cfrac%7B%5Cmathrm%7Bd%7Du%5E%7B%2A%7D%7D%7B%5Cmathrm%7Bd%7Dx%7D+-+u%5E%7B%2A%7D%5Cfrac%7B%5Cmathrm%7Bd%7Dv%7D%7B%5Cmathrm%7Bd%7Dx%7D%5Cbigg%29+%5Cbigg%5D_a%5Eb&bg=ffffff&fg=111111&s=2&c=20201002)

![= p(a) \bigg[\bigg(v(b) u^{\prime}(b)^{*} - v(a) u^{\prime}(a)^{*}\bigg) + \bigg(u(a)^{*} v^{\prime}(a) - u(b)^{*} v^{\prime}(b)\bigg)\bigg] = 0](https://s0.wp.com/latex.php?latex=%3D+p%28a%29+%5Cbigg%5B%5Cbigg%28v%28b%29+u%5E%7B%5Cprime%7D%28b%29%5E%7B%2A%7D+-+v%28a%29+u%5E%7B%5Cprime%7D%28a%29%5E%7B%2A%7D%5Cbigg%29+%2B+%5Cbigg%28u%28a%29%5E%7B%2A%7D+v%5E%7B%5Cprime%7D%28a%29+-+u%28b%29%5E%7B%2A%7D+v%5E%7B%5Cprime%7D%28b%29%5Cbigg%29%5Cbigg%5D+%3D+0&bg=ffffff&fg=111111&s=0&c=20201002)

 and
and  are eigenfunctions corresponding to two distinct eigenvalues.
are eigenfunctions corresponding to two distinct eigenvalues. is an eigenfunction corresponding to an eigenvalue
is an eigenfunction corresponding to an eigenvalue 





 , so the eigenvalues must be real. In particular, this must be the case for regular and singular Sturm-Liouville problems, and for Sturm-Liouville problems involving periodic boundary conditions.
, so the eigenvalues must be real. In particular, this must be the case for regular and singular Sturm-Liouville problems, and for Sturm-Liouville problems involving periodic boundary conditions. denote two eigenfunctions corresponding to distinct eigenvalues
denote two eigenfunctions corresponding to distinct eigenvalues  respectively. Then we have
respectively. Then we have



 , of a Sturm-Liouville problem with specified boundary conditions also form a complete set of functions (I will not prove this here), which means that any sufficiently well-behaved function
, of a Sturm-Liouville problem with specified boundary conditions also form a complete set of functions (I will not prove this here), which means that any sufficiently well-behaved function  exists can be represented by a Fourier series of the form
exists can be represented by a Fourier series of the form
 are given by the formula
are given by the formula

 has an infinite set of eigenvalues
has an infinite set of eigenvalues  and corresponding eigenfunctions
and corresponding eigenfunctions  ,
,  , which are orthogonal and form a complete set. We will assume that the solution of the inhomogeneous differential equation above is an infinite series of the form
, which are orthogonal and form a complete set. We will assume that the solution of the inhomogeneous differential equation above is an infinite series of the form
 are constants, and we will find these coefficients using the orthogonality of the eigenfunctions. Since for each
are constants, and we will find these coefficients using the orthogonality of the eigenfunctions. Since for each 


![= \sum_{k=1}^{\infty} a_k \bigg[\frac{\mathrm{d}}{\mathrm{d} x} \bigg(p \frac{\mathrm{d} \phi_k}{\mathrm{d} x} \bigg) + q \phi_k\bigg]](https://s0.wp.com/latex.php?latex=%3D+%5Csum_%7Bk%3D1%7D%5E%7B%5Cinfty%7D+a_k+%5Cbigg%5B%5Cfrac%7B%5Cmathrm%7Bd%7D%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%28p+%5Cfrac%7B%5Cmathrm%7Bd%7D+%5Cphi_k%7D%7B%5Cmathrm%7Bd%7D+x%7D+%5Cbigg%29+%2B+q+%5Cphi_k%5Cbigg%5D&bg=ffffff&fg=111111&s=2&c=20201002)
![= \sum_{k=1}^{\infty} a_k\big[- \lambda_k w(x) \phi_k\big]](https://s0.wp.com/latex.php?latex=%3D+%5Csum_%7Bk%3D1%7D%5E%7B%5Cinfty%7D+a_k%5Cbig%5B-+%5Clambda_k+w%28x%29+%5Cphi_k%5Cbig%5D&bg=ffffff&fg=111111&s=2&c=20201002)


 we can multiply both sides by
we can multiply both sides by  and integrate. By orthogonality, all the terms in the sum on the right will vanish except the one involving
and integrate. By orthogonality, all the terms in the sum on the right will vanish except the one involving  . We will get
. We will get






